Everyone is actually underestimating stickiness. The near billion users OpenAI has is actually a real moat and might translate into decent chunk of revenue.
My wife, for example, uses ChatGPT on a daily basis, but has found no reason to try anything else. There are no network effects for sure, but people have hundreds and thousands on conversation on these apps that can't be easily moved elsewhere. Understandable that it would be hard to get majority of these free users to pay for anything, and hence, advertising seems a good bet. You couldn't have thought of a more contextual way of plugging in a paid product.
I think OpenAI has better chance to winning on the consumer side than everyone else. Of course, would that much up against hundreds of billions of dollars in capex remains to be seen.
So in summary OpenAI are basing their valuation of 285 billion on the moat of 'users won't be arsed to download a different app'???
Seems optimistic when there is very little intrinsic stickness due to learning the UI or network effects. Perhaps a little bit chat history - but not 285 billions worth.
Also completely ignoring the fact that most devices things will start to come with the same features directly built into the device/app - and the largest market will be as a commodity backend api that the eventually users won't know or care if it's a google or openai model.
As I see it, they need to be doing stuff nobody else can ( in either price or performance ), otherwise it's hard to justify the valuation.
> the moat of 'users won't be arsed to download a different app'???
don't even need to download anything, just open your browser and go to google.com to use gemini
last week end at a party, I've seen non-tech people who previously used chatGPT on their phone, just go on google to ask stuff to AI (they have no idea it's gemini and don't need to know)
if you are not looking for having some king of relationship with an AI (I guess chatGPT it's still the best for this use case), then in my opinion google won, you can't beat google search + gemini summary all at once for free with a single prompt
> So in summary OpenAI are basing their valuation of 285 billion on the moat of 'users won't be arsed to download a different app'???
Apple would like a word with you.
Edit: I'm talking about how most of Apple's profits are a result of of people's reluctance to download new apps. (the whole imessage lock in is an example).
Of course unless chatgpt comes preloaded in phones it doesn't affect them. I just found the above comment funny.
These models respond differently and have their own "personality". Even in coding, there are people who swear by one model over the other. I know engineers who just stick with Claude and could not care to try Codex. For them, if it's not broken, why fix it?
> Even in coding, there are people who swear by one model over the other
I just swear at the models. =P But jokes aside, I liked Claude Code and found it a big productivity boost for a month or two. Then the honeymoon phase slowly ended and I realized how much of its code I was rewriting myself. I don't use assistants anymore except to summarize changes for commit messages or PRs (and then I rewrite those summaries).
Not sure how many developers are like me, but I am very open to Claude, very open to Gemini, open to open source models (including gpt-oss), but am very reluctant to use frontier OpenAI models. The Microsoft distrust runs extremely deep, the browser authentication dance demanded of users for ChatGPT was the most extreme of the major frontier models, and early OpenAI API service stability was absolutely terrible. Llama had my back back then.
Apple has offered products with little value over competitors for a long time now, but they still get to command a large premium on their products because "the vibes are right".
When engineers analyze things they look at the specs, stats, and metrics. When consumers analyze things they look at what others are doing, feel for vibes, roll into the convenience, and stick with the familiar.
> The overwhelming volume of Apples sales comes from people who wouldn't notice if their device was running 2016 level hardware.
How could we possibly know this? This is just an argument from elitism, as though the plebes should be happy playing Farmville on their gateway computers, while us haughty developers sit in our ivory towers and herald in the end of the anthropocene using machines we can actually appreciate.
They make a good point. Apple's most-popular device is a smartphone that doesn't handle workloads any heavier than Snapchat or Instagram. The value prop of the iPhone is not rooted in the performance or battery life (as Liquid Glass showed us) but just the branding.
Apple makes more money selling iPhone accessories than they make selling Macs. The desktop market share isn't going up, the Mac's lifeline is depreciation of old hardware to force Mac owners into the upgrade cycle: https://gs.statcounter.com/os-market-share/desktop/worldwide...
I think the point was supposed to be default
apps in an OS, similar to default search
engine.. What I am missing is that OpenAI
is in no way that default. Every OS, browser,
etc should be able to find a more profitable
default than sending someone to OpenAI.
Apple is one of the very few companies committed to (hardware) quality. They make sure their entry level models are very decent. You can't buy a apple product that is complete shite.
Yes, the software side is getting worse in recent years but is it at least slightly better than the competition for average consumers.
Plus being a tech monopolist they can offer a whole ecosystem of software and hardware that works great with each other. So the value proposition is greater than the sum of its parts.
That is the problem with OpenAI, they have only one thing. Google can bleed money all day long and they don't need to care because they have other profitable business ventures.
The way to make money with LLMs is to either be technically superior which only works short term until the competition catches up or create a monopoly. The second option is dead in the water with the advent of the Chinese models. I guess they can lobby to have them banned and create a cartel with their other US based competitors. Otherwise they are screwed. That is why they are allowing military use of their model now. They need that sweet government money to survive. Also they keep talking about AGI so the government gets scared about the Chinese reaching it first and supports them. Complete scam.
it's a very different world when you switch from an iphone to an android phone or vice versa. However, Claude.ai and chatgpt.com are not very different at all. If one has ads and the other does not, it's easy to switch.
If a setting is default, if an app is presented on the front they'll continue to use it as it is. The crowd here always overestimates how competent/interested the general public are in these things.
99.9% (source: my life) of users never even open the second level of the settings app. 99% don't even open the settings app. They don't know how much they can even change or care.
iPhones auto surfacing airpods to pair with was not for convenience it was a necessity. People don't know how to pair with bluetooth. Now android does it as well.
There's a generation that grew up with appliances that accounted for their mistakes rather than failing. There's no need to learn or understand how something works.
It took Google a decade before they released Chrome so OpenAI has plenty of time to have a Chrome moment. Maybe it'll be something that comes from the OpenClaw acqui-hires?
During that time - as was pointed out elsewhere - Google search was simply way better than the alternatives - embarrassingly so. It also paid the Mozilla foundation lots of money to be the default.
Google was clearly superior fo a long time. They got close to 90% before enshitification started in earnest. We are not at that stage yet with AI chatbots.
Also, Google benefited from being the default on mainstream OSes. When people have to download an application, getting one or the other does not take more effort. Yes, OpenAI being tightly integrated within Windows, Android, and iOS would be a moat. That’s not the case and it is unlikely to happen. Google will go with their own and Apple won’t put itself in a situation where they are reliant on a single company, they got burned enough times.
Also which search engine was the default was a massive factor - that's why Google paid for that.
If Google hadn't controlled Chrome, and or paid for defaults - they could have pretty much lost all their traffic overnight - ( if they weren't better ).
You'd be surprised that most people don't find any pleasure in comparing and trying out different software. They're looking for something which works and ChatGPT is just an amazing product. People aren't going to look for something else unless it breaks for some reason.
Most people who have a vehicle aren't trying out different motor oils, or comparing every month if they should change model, etc.
> As I see it, they need to be doing stuff nobody else can ( in either price or performance ), otherwise it's hard to justify the valuation.
Do you have a car? What does it do that no other car does?
I think you're right about stickyness up to a point.
Cultural defaults seem unchangeable but then suddenly everyone knows, that's everyone knows, that OpenAI is passé.
OpenAI has a real chance to blow their lead, ending up in a hellish no-man's land by trying to please everyone: Not cool enough for normies, not safe enough for business, not radical enough for techies. Pick a lane or perish.
Not owning their own infrastructure, and being propped up by financial / valuation tricks are more red flags.
Being a first mover doesn't guarantee getting to the golden goose, remember MySpace.
Hotmail is a good example too. I remember it being pretty ubiquitous, at least for the 'personal email' crowd, and it seemed implausible that people would give up on what was often their main email 'location' for another offering without being able to transfer their often important and personal stuff. then gmail came along.
The internet and the surrounding context changed so fast that it made little sense to cling to old email addresses made in the old context. Gmail represented the 'new internet' and old patterns became obsolete (less subversive, more mainstream/corporate). When there's a seismic shift in usage patterns that's when all bets are off regarding where everyone lands. Being the first mover means little here. If the way people interacted with AI underwent a massive shift, OpenAI would likely get left behind. The only safe bet is to invent your own killer.
Younger people might not realize or remember this, but when GMail came out it was HUGE. Like, I remember it was invite-only for a while and getting an invite was a really big deal. In retrospect that was some genius marketing by them (also just a way better product, at the time)
Also switching email was a lot easier back then. Nowadays if you're using gmail as an auth provider it's very hard to completely abandon an inbox without a lot of friction. Back then all your logins were separate anyway.
Interesting point. I guess people liked the convenience of unlimited storage even more than they liked the convenience of keeping the same email address. In a way they traded one convenience for another.
I don't remember that detail, but I do remember most people not treating their inbox as an archive at the time. So there was less friction to switch to gmail, and more reason to do so due to the "real time" ticking storage amount of gmail, which then became an archive (again for most people).
> I do remember most people not treating their inbox as an archive at the time.
Indeed. For me, the step was gmail. With its humongous 1GB of storage, that was the moment when I stopped having to delete stuff to save space. It’s funny because a lot of people I know who were already older at that point kept the habit of deleting emails, even today.
Isn’t that exactly what’s being discussed re: OpenAI? They seemed unstoppable a few years ago, but have lost quite a bit of reputation and their position of technical lead.
in the tech world, maybe. All my 'normie' friends are using ChatGPT though and have no concept of their reputation, nor intention of switching. Most people I know are hardly even aware of alternatives, even of Gemini, though everyone has a Google account.
I personally also use ChatGPT and have zero reason not to, currently. I might switch if they royally mess up, but everything they've messed up has been fixed within a day.
IBM was a special case, I'm not sure there were many markets so thoroughly cornered like IT was for about 3 decades. I guess telephone (AT&T) was similar.
Literally every industry has examples of businesses that don't excel at anything and still do well enough to carry on. In fact, in most industries, it's actually hard to see any business that's clearly leading on any specific front because as soon as it becomes an obvious factor in gaining market share the competing businesses focus on that area as well.
Yeah. Vauxhall/Opel has always been my go-to example here. Their cars excel at nothing. They’re not especially stylish. Not the fastest or nicest to drive. Not unusually efficient. Not particularly reliable or guaranteed for a long period. By no means the cheapest. They don’t even achieve a sweet spot of averageness across all these things. Yet people have somehow carried on buying them over decades.
Jeremey Clarkson called the Astra "the most boring car ever made". I loved both of mine - they always got me and my stuff where I needed to be, and were easy to fix.
The last one, a 2007 model that has now moved on to my younger sibling, might be the last "simple" car.
> Everyone is actually underestimating stickiness.
I think you're underestimating how fickle consumers are, and how much their choices are based on fashion and emotion. A couple more of these, and OpenAI will find itself relegated to the kids' table with Grok and Perplexity. https://www.technologyreview.com/2025/08/15/1121900/gpt4o-gr...
My wife, for example, uses [Netscape Navigator] on a daily basis, but has found no reason to try anything else. There are no network effects for sure, but people have hundreds and thousands on [bookmarks] on these apps that can't be easily moved elsewhere.
At this moment, I agree. Your average person (which doesn't really exist) has already been exposed and trained on ChatGPT. Arguing moving to another "chat" experience has not gone well, for example Bing, etc. Pretty sure Google had the "box" figured out first and won. I think people overthink how much effort people are willing to put into "change". There is nothing wrong with staying put if it works, after all, there is an unlimited number of other things happening in this world besides AI.
I imagine the stickiest customers would be large enterprises. You aren't going to get the evangelists to stick on a single model provider, so their best bet is probably employees who are going to have their choices dictated to them by whoever purchases the softare. (Especially in large enterprises where using an unapproved AI provider is likely not allowed, or the AI is imposed on the workers.) The question then is, how do you differentiate yourself in enterprise sales? As much as people seem to dislike Copilot, from a business standpoint "buy the extra microsoft thing in our current contract" or "buy the extra google thing in our current contract" could likely be a lot cheaper/less friction.
Is she paying for it? That is the only question that matters in the end.
For myself, I use LLMs daily and I would even say a lot on some days and I _did_ pay the 20€/mo subscription for ChatGPT, but with the latest model I cannot justify that anymore.
4o was amazingly good even if it had some parasocial issues with some people, it actually did what I expect an LLM to do. Now the quality of the 5.whatever has gone drastically down. It no longer searches web for things it doesn't know, but instead guesses.
Even worse is the tone it uses; "Let's look at this calmly" and other repeated sentences are just off putting and make the conversation feel like the LLM thinks I am about to kill myself constantly and that is not what I want from my LLM.
>Is she paying for it? That is the only question that matters in the end.
Don't underestimate advertising. Noone pays for Facebook or Google search. Yet the ad business with a couple billion users seems profitable enough to fund frontier LLM research and inference infrastructure as a side-gig in these companies. Google only rushed out AI overview because they saw ChatGPT eating their market share in information retrieval and Zuck is literally panicking about the fact that users share more personal details with OpenAI than on his doomscrolling attention sinks.
OpenAI is talking out of their ass with their advertising plans. Meta and Google are an advertising duopoly, extremely anti-competitive, and basically defrauding their own customers. OpenAI can't just replicate that.
Worse still is that OpenAI has no competitive edge. All the hype around their advertising plans is based on the idea that they can blend the ads right into the response, a turbocharged version of Native Advertising.
This is explicitly illegal. Very explicitly.
The US' FTC may have been declawed by the current US government, but the rest of the west will nuke them from orbit over it. Doubtless OpenAI will try some stunt alike marking the entire LLM response as "this is an ad", but that won't satisfy the regulators.
This only gets worse with further problems. An LLM hallucinating product features is going to invoke regulator wrath as well, and an LLM deciding to cut off the adcopy early will invoke the wrath of the advertiser.
> Yet the ad business with a couple billion users seems profitable enough to fund frontier LLM research and inference infrastructure as a side-gig in these companies
Also important: Not anymore. The tech giants are now issuing quite a lot of debt to pay for the AI plans.
Maybe I am underestimating how suggestible average people are as someone who has never in their lives clicked on an ad I just can't see ads being anything but a deterrent for using the service
You sure are. And it sounds like you are also underestimating the effect yourself as well. In fact this perception is so common that there is even a name for it in psychology: Third-person effect. Many people believe that advertising does not affect them. But ironically, the more you believe so, the more likely you are to fall victim to particular types of advertising. And in general your response to ads will be very similar to everyone else's. These "annoying" ads that you "would never click on" are just badly personalized or badly placed ads. That's the only type that gets stuck in your mind when you think of ads, based on your personal biases. But the major tech companies have spent the last one-and-a-half decades on perfecting the psychology of advertising. You might think you are immune, but you are certainly not. Every buying decision you have made in the last 10 years was almost certainly influenced to some degree. Just not always consciously. And I'm willing to bet that a lot of buying decisions were already heavily influenced by ChatGPT, even before their shopping feature. OpenAI just didn't profit on them as much as they could.
Influenced to some degree sure, weather influences me to some degree, but I truly feel like ads aren't affective on me. Unless we broaden definition of ads to something like sponsored content. I have bought some TTRPG rules sets after I have seen them being played in a sponsored video, but I still have never clicked an ad on a page and bought something.
And I actually have tried to use ChatGPT to buy something. I have asked it to search for specific items from EU stores so I wouldn't need to pay import taxes, but usually it fails. It either suggests Global stores which ship from US or China or it suggests different products than what I asked for.
If ChatGPT or whatever LLM I was using could actually link me the products I wanted without me searching for them they should get a commission for sure, but we sure aren't there yet.
However, I believe an ad it still influences you subconsciously as long as it is in your sight line.
I wouldn't be surprised if there is a lot of investigation into subtly slipping advertising in the LLM responses the way Korean dramas have product placement right in the storyline (Subway, bbq chicken, beverages, makeup, etc).
Subtle things like the guy in CSI Miami talking about how good Subway is for 5 minutes?
Of course stuff in the world influences me, I am still a human. Still I have never clicked an ad and bought something. I simply don't get who would. Same as with the super market placing candy and stuff next to the cashier to get people to buy more, I have never been swayed by those because when I go to the store I am always on a mission and know before hand what I am buying.
It would be cool to see all the times I have been influenced into buying something because of subconscious advertisement, but that's kind a impossible so all I can do is deny it and of course all marketing people will say that I am wrong.
And we can argue forever what counts as an advertisement. For example I recently bought a new mouse pad, I wasn't particularly looking for a specific one, just something fun and bright and as I was browsing a web store they had a cool design for half off and I bought it. Maybe that was targeted advertisement, but I had already made the decision to buy a new mousepad and had been browsing on and off for few weeks, so was it really? I would argue not.
You seem to have defined ads as "obvious calls to action that end up in me buying it for sure". That's a pretty narrow view of marketing, but it does feel like you are aware that there may be other forms as you provide examples across the thread. It comes off as some form of elitism, where you deem the simplest ads as ineffective on yourself (but work on "average people") - but then go on to mention things like discounts and sponsorships, which to most are obvious marketing ploys too. No judgement, but maybe reflect on this?
Is discount really an ad? Like if I had already made a decision to buy a thing and now I paid less for it was it really a working ad?
Also sponsored content is way different than having ads on a website or in an app or what kind of ads do you think GPT will have?
And you are definitely judging me. When people say “ads” that is pretty specific thing that they mean. If you broaden it to mean everything then I can’t argue as there is no point.
There is two options either ads (as in those things every one blocks with uBlock Origin) do not work on people OR they do work on most people but not on me, if anything they are a deterrent from buying that product.
> Any message designed to promote or sell a product, service, or brand, where there is a material connection between the speaker and the advertiser.
Yes, a discount is an ad - sometimes by the brand/manufacturer to get you to buy their product instead of a competitor, or by the seller to sell that product over others (for even mundane reasons like stock clearing).
Yes, sponsored content is an ad. The content creator is reimbursed for their output that is used to convince viewers to perform some purchase activity, usually over alternatives.
You’re really severely restricting the definition yourself by claiming an ad is “things that ublock origin” blocks. They can’t block physical banners and billboards or TV commercial breaks - does that now make them not ads? Whether you intended to buy something again doesn’t disqualify something from being an ad. In fact, that’s often when an ad is most effective - to buy the one they show you, instead of one you haven’t heard of or considered.
Ads aren't just for click through, they are for suggestions, and mind share as well.
You can't click on the budweiser logo when watching super bowl ad. But if you sit in your chatgpt window all day then it's probably worth it for advertisers to expect to build familiarity with brands they advertise.
Really depends what the ads are. If they are popups or other intrusive ads the product will just die. If they are subtle hints in the text how are you going to track it. I don't know, I just don't believe in ads, but then again I am dirty commie so who am I to tell you not to
That’s not the point. The point is that brands build awareness through ads that don’t require clicking and this ha effected you whether you want to admit it or not
Imagine subliminal messages being sent in the llm responses carefully created for max impact on you. I’m sure many companies will pay to recommend their product on ChatGPT.
not necessarily, if openai managed to monetize free users. Could be through advertising, or integrations with marketplaces on commission (e.g. order your next Hello Fresh through ChatGPT? Get recommended a hotel?)
They could succeed where Alexa failed. A free user can even bring in more than a paid user if you look at some platforms like spotify, where apparently there is a large chunk of free users generating more income through ads than if they would pay
I was researching CAVA ( due to the crazy earnigs announcement yesterday ) and it was displaying some nice links to the website, all suffixed with ?utm=chatgpt
Most potential customers wouldn't ever think in terms as "justifying" a €20 purchase when the product is great.
ChatGPT (and competitors) is an incredibly high value tool, and €20 per month is nothing for somebody who wants or needs it. It's just a matter of if they use it enough to start hitting the daily limits.
> Everyone is actually underestimating stickiness. The near billion users OpenAI has is actually a real moat and might translate into decent chunk of revenue.
I’ve got a small-ish sample of friends who are regular people and use various AI chatbots because mobile phone providers now commonly bundle an AI subscription with their services. People seem to switch between Perplexity, Claude, and ChatGPT without any trouble. It does not look sticky at all to me and the half-a-percent difference in benchmarks we love to obsess about does not translate at all in increased user satisfaction.
I hear the claim that people already have their conversation on ChatGPT and can't move them. I'm curious, what are these discussions like? I've never continued an old discussion, I just start a new one every time I have a question. If the discussion is long, I often start a new chat to get a blank slate. My experience is that the chat history just causes confusion.
So I'm curious to understand: What are the discussions like that people go back to and would lose if they moved to another platform?
In my experience non-technical folks quite dig the memory feature. For me that's kinda context poisoning as a service, but I know people that get value out of it (or at least strongly feel they do). Not sure how one would migrate that.
It's one of those super easy things that 90% of the users just never do - like changing their default search engine, export their social graph, install ad blockers, etc.
Regardless of whether there is value in chat history or not, for some people it is important.
Back in the day during the music streaming wars there were tons of "move your playlists from A to B" services. Streaming services could not hold on to customers because all their playlists were on there.
I'm sure that similar services will pop up for chatbots.
Also, you can always just ask your chatbot to generate a file with your chat history, given that it's all part of the context anyway.
I'm curious from the other direction, what are the conversations like if you feel they are easy to move?
Do you have the memory feature disabled? I have the feeling this in particular is doing absolutely loads behind the scene, e.g summarising all conversations and adding additional hidden context to every request.
I can start a new chat in the UI right now, ask it what my job is, what my current project is, how many kids I have, what car I drive etc. It'll know the answer already.
I think it's this conversation history - or maybe better yet if we think of it as this "relationship" - that people are saying is going to make it hard to move.
I ask for code snippets, occasional recipes, translations... I don't have memory enabled. I start a new chat for each question. At times I ask things in different languages, if the question is tied to culture or location. If I notice I asked the wrong question, I start a new session instead of continuing the old one, so it doesn't try to merge the questions somehow.
I don't see any benefit in it knowing anything about me. Instead I'm usually quite vague to avoid biased answers.
yeah the 'sessions' approach is probably going to be deprecated. one continuous chat is where it's at , perhaps with some bookmarks on the side for easy access
or perhaps a thread-based chat like reddit or HN, where you can branch off an older conversation with yourself
> but people have hundreds and thousands on conversation on these apps that can't be easily moved elsewhere.
Except these aren't conversations in the traditional sense. Yes, there's the history of prompts and responses exchanged. But the threads don't build on each other - there's no cross-conversational memory, such as you'd have in a human relationship. Even within a conversation it's mostly stateless, sending the full context history each time as input.
So there's no real data or network effect moat - the moat is all in model quality (which is an extremely competitive race) and harness quality (same). I just don't think there's any real switching cost here.
I use OpenAI a lot on the paid plan via the UI. It now knows absolutely loads about me and seems to have a massive amount of cross conversational memory. It's really getting very close to what you'd expect from a human conversation in this regard.
Sure the model itself is still stateless, and if you use the API then what you say is true.
But they are doing so much unseen summarisation and longer context building behind the scenes in the webapp, what you see in the current conversation history is just a fraction of what is getting sent to the model.
Baffled that someone tech literate would be boasting about this in the year 2026. I mean, you do you, we all have different priorities and threat vectors, but this is the furthest from what I would personally want.
It's not boasting, I'm not sure why what I wrote would come across that way. I'm describing how I use a product and the functionality it presents to me.
But yes, it's an emerging area and I am questioning if I am sharing too much with it. I 100% would not want my chat histories exposed.
Saying that though, facebook can read my highly personal messages, google every email, my phone is tracking my every move, I have to sign up for random janky websites for my kids school where ther medical info is stored, etc.
LLM chat history presents a new risk and a different set of data, but it's a crowded minefield already.
This is the same as when Google got big (and Facebook, etc...). We have some privacy focused competitors (Kagi, etc...) but most people are quite happy to just give Google (and worse, Facebook) everything.
AI is just a new technology but this has been ramping up for decades now.
I see people who have conversations spanning months. They don't start new threads and instead go back to existing threads to continue the topic. They also reference the prior threads discussion many times.
This would feel like a switching cost for people who use the system that way.
Is there more detailed information how this works? I used to assume that it can be beneficial to switch to a new chat to avoid having took much irrelevant context in the interaction. How does this personalization happen, how does it decide which parts are relevant from one conversation to another?
It doesn't seem like there's a way to inspect or alter what kind of information Gemini had saved as "important information" about me (apart from deleting chats entirely, apparently).
On the web app, I see the "temporary chat" option but no toggle. It tells me temporary chats aren't used for model training. I thought I remembered that chats of Pro customers aren't used for that in any case. Hard to keep track of all this stuff.
Ultimately, I think the crossover memory is useful, but I'd really like to know exactly what's in there and an ability to validate/adjust, not just on/off.
Model training is completely different than keeping a summary of chats on the side and injecting it as context.
In my Gemini app, when k click new chat and click the filters button I have “Personalize Intelligence: Personalize chat when helpful.”
It is on every time I click new chat. Maybe you need to enable it in settings first. I can disable it to have a clean chat without personal context, but preserve the chat history unlike temporary chat.
I understand they are separate processes (compacting memories vs training new models), it just surprised me to read that my chats are used for training.
This is how it's presented: "Temporary chats Opens in a new window don't appear in Recent Chats Opens in a new window or Gemini Apps Activity Opens in a new window and aren't used to train models or personalize your experience."
I'm guessing you're maybe on iOS? I don't see these UI elements, not in the App on my phone nor in direct web access.
I think that kind of inertia mostly lasts as long as there is no financial incentive to move. A ChatGPT user who is not paying anything to OpenAI is of little benefit to them, and has little incentive to switch. However if OpenAI start trying to make money off those users by adding advertising, or removing the free tier, then things may change. Google can afford to subsidize chat from their other revenue streams, but OpenAI can't.
>However if OpenAI start trying to make money off those users by adding advertising, or removing the free tier, then things may change.
Tech forums tend to be in a bit of a bubble. People said the same thing about Netflix and it just quickly became their most popular sub. People don't care about advertising unless it's really obnoxious.
The idea that people will unsub en masse once Open AI starts rolling ads is a pipe dream. And the kind of user that won't pay and won't suffer some ads is the kind of user nobody wants.
Stickyness absolutely helps. But it won't get you anywhere close to a MAG7 operating margin. I think we are already seeing the start of price wars. I cancelled my ChatGPT subscription once i realized Gemini Pro was included in my Google Workspace and never looked back for a second.
I am arguing that “distinctly better” isn’t the most important thing in consumer products. Habits, familiarity, and individual taste at far far more important.
People just build affinity to products. The vast majority of people buy the same brand toothpaste they grew up with. “Better” isn’t even a consideration.
Idk, habit and the devil you know are powerful as hell. Google has enshittified search nearly beyond imagination, but it's still where the vastly overwhelming majority of people search.
What free search engine today performs significantly better? No seriously Google sucks and I want an alternative. Do I need to pay for Kagi to get decent search?
Anecdata point: I canceled my ChatGPT pro subscription last year over some shitty thing Altman did at OpenAI and easily moved over to Claude. The only thing I took with me was the system prompt or whatever it's called, I couldn't care less about my conversation history. I'm planning to do the same thing with my Claude subscription if Anthropic kowtows to the Pentagon. These services are not sticky at all IMO.
Anthropic already decided to do business with the "killing people" department of the government. I think the battle was lost there, rather than whether or not they cross a line in the sand they drew to act as if they're the ethical AI company despite making products that are used to kill people. I'm sure the result of this battle will be some compromise that allows the Pentagon to get whatever they want while offering a fig leaf to Anthropic to continue their ethicality show.
Yes, I just caught up on all the Anthropic x Pentagon news this morning. I've canceled my subscription and let them know why in the feedback. It's too bad because I liked the Claude models, but I can easily swap the Claude app out with DuckDuckGo and use one of the open models my DDG subscription supports.
Anthropic donated $20 million to Public First Action[1], a PAC that promotes Republican Senator Marsha Blackburn and her sponsored Kids Online Safety Act (KOSA)[2], a bill that will force everyone to scan their faces and IDs to use the internet under the guise of saving the children.
The legislative angle taken by companies like Anthropic is that they will provide the censorship gatekeeping infrastructure to scan all user-generated content that gets posted online for "appropriateness", guaranteeing AI providers a constant firehose of novel content they can train on and get paid for the free training. AI companies will also get paid to train on videos of everyone's faces and IDs.
As for why Blackburn supports KOSA[3]:
> Asked what conservatives’ top priorities should be right now, Senator Blackburn answered, “protecting minor children from the transgender [sic] in this culture and that influence.” She then talked about how KOSA could address this problem, and named social media platforms as places “where children are being indoctrinated.”
If Anthropic, the PACs it supports and Blackburn get their way with KOSA, the end result will be that anything posted on the internet will be able to be traced back to you. Web platforms will finally be able to sell their userbases as identifiable and monetizable humans to their partners/advertisers/governments/facial recognition systems/etc. AI companies will legally enshrine themselves as the official gatekeepers and censors of the internet, and they will be paid to train on the totality of novel human creativity in real-time.
I'd probably swap to one of the open models available through my DuckDuckGo subscription. I don't keep up with the AI hype so I don't know what options exist out there beyond ChatGPT, Claude and Gemini right now.
In theory you can export your data from ChatGPT under Settings > Data Controls. In practice, I tried this recently and the download link was broken. Convenient bug I must say.
300 million users in 2007 is mighty impressive, the internet was not absolutely ubiquitous like now, mobile access to it was in its infancy. Relatively speaking it is as impressive as 1 billion users in 2026.
Netscape had a 90% market share in 1995. If OpenAI is metaphorically netscape, what prevents its competitors from prying away customers every day? What prevents google/facebook/microsoft from using their position to bundle chat experiences? Especially if the tech is a commodity and OpenAI's models are about as good as everyone elses?
In 1995 no one used the web still. Sure, we all did, but it was pretty niche. I think you could argue that chatbots are niche as well, but the user base of OpenAI is way larger now than Netscape in 1995. Netscape had probably 25 million users at the end of 1995. ChatGPT has about 800 million.
I've actually been using the Gemini app more because it auto-deletes old history. I like using LLMs without thinking this is going to stick around forever.
Models are relatively interchangeable for day-to-day use anyway.
I don’t know how much of an anecdote it is, but all the non-tech people with whom I talk about IA only know chatGPT. Competition is either non existent or the same thing. Among those, no one wants to pay the service, they just stop using it when limits are reached. I can’t say which users can turn the market around but chatGPT is indeed burned in the mind of many and because they don’t care about tech and are not interested in tech they won’t search for any other service it seems. Even after many discussions they don’t remember the names of other IA I told them
I would bet 100% of those people have either Apple or Android phone in their pocket. Android users already have easy access to Gemini, and Apple's Siri is going LLM soon enough as well.
Google and Apple just need to push their AI assistants hard enough, and most of the moat OpenAI has will be gone.
I believe specifically for Microsoft, they did bundle a default replacement for chatGPT in a lot of different places (Bing chat, Copilot) which use OpenAI models! But the end product is notably worse than native interface. There is a bare-minimum-level of usability required.
For chat apps, good enough is good enough. For something as universally useful and easy to use as ChatGPT, the bar is higher. I don't want to comment on the financial feasibility, but whatever Microsoft put out has been a complete flop even when free, making ChatGPT $8 subscription seem worth it in comparison
> But the end product is notably worse than native interface.
That was my point - a lot of superior products were eaten by poor bundled replacements.
Last I checked, copilot has more users than ChatGPT simply because users are using it from within Excel, Word, Outlook and Teams, without even knowing that they are using copilot. It's bundled into Windows.
Right now, copilot is more useful to users than ChatGPT because it is embedded into their workflows.
They're losing market share and the growth of active user plateaued. They captured all the normies who learned about llms on TV but these people will never spend a cent as you said.
I’m not rooting for open AI but OpenRouter is a very self selecting group. Most API users of Anthropocic or OpenAi would just go through the normal API
I'm surprised how many of my technical team use free ChatGPT in their personal lives. The rest have Claude subscriptions. I'm the only one with ChatGPT and Claude subs and I'll be switching from Claude Pro to Ckaude Max and cancelling ChatGPT, since I only use it when I hit my Claude quota.
They are more easily moved than other data honestly. You can use chat gpt to build your own chatbot and then export all of your data from openai and load it into the new chatbot.
I think defaultism plays a huge role. If your wife's next smartphone or TV or whatever comes with AI made by a different company, I think she won't really care and use that if it's good.
By the way this is a perfectly rational stance. If the supermarket next to me stopped stocking Coca Cola, I would just by Pepsi.
ChatGPT has a good name. It's weird and awkward but it still rolls off the tongue. And I am saying that as a non native English speaker because the name has been migrated to other languages with the English pronunciation.
In comparison, Claude's name is very bad, it just doesn't sound right and people might mishear me when I say it. I never say "Claude" when talking to other, especially non-technical people, and instead say "ChatGPT" even though I am using Claude exclusively.
Google has another problem - they advertise their models as separate products. There is Gemini and there is Nano Banana, also Nano Banana Pro. But they are all somehow under the same product which is still called Gemini. I understand the distinction but I am sure many non-technical people find it confusing.
Claude may seem incongruous compared to the others, however it's the only human sounding name, compared to the robotic "chatgpt" or others that sound generic or bland company names (Gemini, perplexity).
They intentionally chose a more bland sounding name, as, I assume, they wanted to emphasise the "safe" nature compared to their competitors.
As more information comes out about openai, people may choose to move to for other reasons, such as
- Openai adding ads
- Openai's president donating millions to a MAGA PAC
- Openai getting closer to the US military whilst anthropic standing their ground and rejecting them.
- Openai's recent products not being at the top of the benchmarks
> They intentionally chose a more bland sounding name, as, I assume, they wanted to emphasise the "safe" nature compared to their competitors.
A lack of creativity seems more likely to me. It’s a GPT in a chat window.
> Openai getting closer to the US military whilst anthropic standing their ground and rejecting them.
Except they didn’t. They folded faster than a house of cards during an earthquake. It boggles the mind anyone thought they wouldn’t. Ultimately they only care about money and winning.
OpenAI has demonstrated a severe lack of ethics, you're right, it's just hard to know how educated the average consumer is about that. The anthropic-military thing is a big deal but I suspect few outside of the tech world really understand the implications of what's going on.
Anectode: My aunt was talking about how she had a conversation with ChatGPT about how bad OpenAI was and the AI said "we need regulations", and that seemed to satisfy her somehow.
They initially wanted to call it just "Gemini 2.5 Flash Image (preview)" but the Internet stuck with the anonymous codename Nano-banana from LMArena because it's interesting and quirky. Google didn't officially adopt it until several days after the public release, exactly because of what you say. Eventually, not using it in their comms got more confusing because regular people were asking how they can find this Nano banana thing everyone is hyped about.
I don't know but around here common people all say "Chatty" nowadays, and also most people if writing the correct name fail to spell "gpt" right quite often in chat.
Google is sticky too, and has a huge moat around that access (android, browsers).
Google hasn't yet pushed hard into dominating the chatGPT use case, but they could EASILY push out chatGPT if they tried. For example, if they instantly turned their search page to the gemini chat, they would instantly have dominated openAI use cases. I'm not saying they would do that, they will probably go for the 'everything app' approach slowly
I think the use cases of chatGPT and google are not differentiated enough to justify 2 winners
I don't think they have a billion active users who opted-in. Google/Apple/Microsoft are the gatekeepers (for the most part) for retail users and they decide who is on by default. The USG isn't going to step-in and the EU won't step in either.
So I suspect that Google will lean into Gemini, Microsoft will lean into OpenAI, and Apple ... it's a tough question what they do in the longer term.
For business users it's a different story and I see room for Anthropic to shine. And then there are the specialty AI services but those are all different markets from the general purpose AI.
I think Google may just end up winning on the good enough / cheap enough dimensions as things get more commoditized in LLM world.. in that they can be the lower cost provider given how vertically integrated they would be compared to OpenAI relying on hyperscalers.
I'm aligned there. I think it will be Google/Gemini gets 50% of the generic market and then OpenAI gets 30% (via Microsoft) and then a long tail. The rest of the vendors will be awesome at their markets (Claude Code for coders) and can handle generic stuff too.
Apple will do whatever they do but it will solely drive users in the Apple ecosystem and they will likely just use one of the other vendors - I'm guessing Google longterm since they speak the same language. There's no point in empowering Anthropic/OpenAI to sit at the top of the pyramid although oddly Apple and OpenAI did that partnership but I feel like that was Apple not thinking ahead.
OpenAI is already building complex user models. And I mean, super detailed user models - where you are from, what you do, what are your most vulnerable weaknesses, what you care about the most and everything else. This is information even the world's largest advertising company would struggle to put together across their fragmented eco-system (Gmail, Search, etc), but OpenAI has all this on a silver platter. And that scares me, because, a lot of people use ChatGPT as a therapist. We know this because of their advertising intent which they've explicitly expressed. Advertising requires good user models to work (so advertisers can efficiently target their audience) and it is the only way to prove ROI to the advertisers. "But, OpenAI said they won't do targeted ads..". Remember, Google said "Don't be evil" once upon a time too..
That's ok, we use ChatGPT only for coding. We should be good, right? Umm, no. They already explicitly expressed the intention to take a percentage of your revenue if you shipped something with ChatGPT, so even the tech guys aren't safe.
"As intelligence moves into scientific research, drug discovery, energy systems, and financial modeling, new economic models will emerge. Licensing, IP-based agreements, and outcome-based pricing will share in the value created. That is how the internet evolved. Intelligence will follow the same path."
So yes, OpenAI has the best chance to win on the consumer side than anyone else. But, that's not necessarily a good thing (and the OpenAI fanboys will hate me for pointing this out).
> They already explicitly expressed the intention to take a percentage of your revenue if you shipped something with ChatGPT, so even the tech guys aren't safe.
Wasn't there already a ruling that LLM output is not protected by copyright?
Yes, but still, targeting is done even in billboards based on the location's demographics based on census data. It's not random. Some countries in Asia (like Singapore, Malaysia) have digital bill boards to target certain demographics based on the time of the day or the estimated crowd demographic at a given bus stop. And a few of them even track eyeballs to count "views" of the ad.
I admit this is a factor I hadn't much considered. I'm sure at some point, if not already, the data collected by your phone will enable the equivalent of a tracking pixel on your physical location, so you can get personalized ads when you step into the subway car: the system will quickly evaluate which rider is most likely to spend money based on ads, and on what, and then an auction will be run in two nanoseconds and the winner will show their 10-second transit clip. Oof.
The saddest part is, the old kind of advertising worked just fine, before all the companies got addicted to AdCrack.
> people have hundreds and thousands on conversation on these apps that can't be easily moved elsewhere.
I just asked it to build me a searchable indexed downloaded version of all my conversations. One shot, one html page, everything exported (json files).
I’m sure I could ask Claude to import it. I don’t see the moat.
Ok so it worked correctly today, for you. How do we know it will continue to do so five years down the road when they are suffocating for cash? The more stuff we have there, the harder it becomes to verify their takeout will have everything.
I'm trying to motivate one or hopefully both of these ideas
- if it is worth backup up or exporting, it is worth doing it early and often
- but more importantly if we backing up and exporting, we should be continuously thinking are we even on the right platform? Does a better alternative exist?
How bad it is if put of 200+ conversations, a couple of those are not exported correctly? Not much honestly.
If I verify some of those and they are ok, I would see no reason to keep verifying all of them.
So far I've not seen anyone complain that their conversations have gone missing. There's a GDPR-style export option that I've used a few times for my own.
The moment openai starts charging for their service properly, people will start shopping around.
See power users such as devs with coding assistants that have model selection dropdowns allowing you to switch on a whim. There is zero loyalty or stickiness in the paying user crowd.
Ads are a little more insidious, and normies aren't nearly as allergic to them as they should be. But whether openAI can achieve their revenue targets by ads alone is a different question.
I am starting to believe that OAI might actually succeed at getting per token inference cost to where it needs to be. Or that it's already there in principle.
Wafer scale compute is a very big deal. Most of HN is probably still unaware that you can get tokens out of one of these devices right now via public API offerings.
Switching llms is like switching a car. Its a bit annoying in the beginning, it responds slightly different and you need to change you subconscious habits before it feels comfortable. Why everyone always complains about new models. So unless there is a very obvious improvement; most users will prefer to stick to their current llm
That has not been my experience at all. My mom and dad were able to switch from ChatGPT to Gemini without any friction whatsoever. I myself round robin between Claude, Gemini and ChatGPT all the time.
I definitely think they’ve nailed the personality better than others too. Gemini and grok are always paragraphs and paragraphs of text to sift through for something that with openai is usually digested to much less
I disagree. So far I've seen people use "Photoshop" and "Google" as verbs. No one uses "ChatGPT" as a verb. People do use ChatGPT but the brand recognition isn't that strong.
My anecdotes are that Google is winning even on consumer side.
As a verb, no, but the product name somehow feels the wrong shape to verb it. I'd say the voice assistants have Google at a disadvantage for similar reasons: "OK Google" is clunky, whereas "Hey Siri," and "Alexa," are not.
But to ChatGPT: when I wander around Berlin, I do overhear people talking about ChatGPT by name.
For all the typical integrated LLM-based "assistants" in other products, I mainly hear people saying things like "I hate it" and "how do I turn this off" and so on, including the one Google has on its search results.
The other pure-play chat-bots that have enough mind-share to even be in the news are Grok (where twitter users seem to like it a lot, even though everyone else up to and including non-US world governments hate it to the point of wanting it banned), Claude (but even then only because of Claude Code), and DeepSeek (because it shows China has no difficulty keeping up with the US). I heard about Mistrial when it was new, but even with the app on my phone I didn't think about it again until about a month ago.
Ask a normal person about Gemini, I'd expect them to think you were talking astrology, not AI.
In my experience, they do, a lot. "I asked ChatGPT" is something I hear a lot. And yes, this example is not using ChatGPT as a verb, but the idea of brand recognition is there; it's just a grammar thing.
I might have sessions I revisit over a few weeks, but nothing longer than that. The conversations feel as ephemeral as the code produced. Some tiny fractions of it might persist long term, but most of it is already forgotten and replaced by lunch time.
Most people I know with android phones, myself included, just use Gemini which is bundled with the OS and has a dedicated button, has excellent data and integration with maps and such.
When it comes to enterprise, non IT companies (banking, insurance, etc) in Europe seem to be defaulting to Google's offerings, Gemini and NotebookLM in particular.
several of my friends named their chatgpt 'Amanda' or 'George' because they talked about real mental issues with it. I don't see them moving to another platform because that's essentially asking them to leave their 'best friend/therapist'.
How do you jump to Gemini from AIO? (I know there's AI mode, but it's separate from the Gemini chat product afaik -- except maybe sharing some model lineage)
As a counter anecdote, my wife stopped using it because it is quite terrible when you ask it about current events. She almost exclusively uses the Grok app now because it has the "best" internet search and current events results
I wish it would be, but it's not. Gemini feels more sluggish, it's relatively overloaded with animations compared to chatgpt. Like most Google products.
I've been testing Gemini as I code on Claude 4.6 and the answers aren't great for coding. ChatGPT has been better. But it did a good job with some personal IRA/401k planning.
It feels like it's only a few months behind though.
And yet Google has search monopoly, is part of mobile duopoly, has almost monopoly on e-mail and data storage, is strong player in office solutions, and owns the biggest entertainment platform in form of YT.
Seems like sluggishness and animations don't mean as much to normal people.
But the (royal) Wife needs to 1) know that exporting is a concept, 2) automating an export is possible, 3) you could ask claude to do it, 4) what an API key is or how to connect services.
My mum, and probably nearly a billion other users, could probably imagine step 1 but not connect to step 2 beyond copy-paste. Most people are still out here sending screen shots of their phones instead of just copying a link or hitting "share" on the image.
I guess if you treat it like a virtual boyfriend. Personally I found the memories to be an anti feature. I start chats to get a clean slate and test new ideas without previous ones polluting the chat.
Exactly. ChatGPT is ubiquitous for the new generation of AI (LLMs) for everyone outside our of bubble. I've spoken to dozens of friends and non-techncial folks about this topic over the last year and not a single one has ever said they use Gemini, Grok or Claude.
OpenAI has by far the strongest brand and user base. It's not even close.
And, when it comes to the product they've been locked in the last few months it seems. The coding models are no longer behind Anthropic's and their general-use chat offering has always been up there at the top.
Completely disagree with this take. I was an early free OpenAI user and switched to Gemini once it got good enough and bundled a bunch of services together to make the paid product free. OpenAI will need distribution to maintain any kind of durable market share. They need to become a bundler of other subs, or else they will just be the next Disney+ or Spotify that needs telecoms (Hah!) to push their paid product onto user's phone bills.
> Everyone is actually underestimating stickiness. The near billion users OpenAI has is actually a real moat and might translate into decent chunk of revenue.
Maybe you're overestimating their "moat" and stickiness. The dust is still settling on this madness and "OpenAI"[1] creates a lot of noise in the market.
These LLMs are being rapidly commoditized, very soon they will become as "boring" as virtual machines or containers. Altman has the exceptional skill to dupe people into giving their money to him. The "infinite money glitch" that he has been exploiting isn't really infinite.
I just hope there'll be a breakthrough with truly transparent LLMs that will stabilize this madness. As I've griped[2] two years ago, I find OpenAI too scummy, and it is unlikely that they will "win" with their sleazy ways.
[1] Air quotes because of their persistent abuse of the word "open"
It's really easy to overcome that -- just sponsor some IndieDevs to flood the internet with scripts and tools to migrate all your conversations from OpenAI. Make it easy for people to switch using a simple process, make sure it's well distributed, and BOOM! Watch their user count drop like a rock. People act like just because a service has a lot of users it can't be destroyed. Anyone who has ever worked at a large web company can tell you otherwise. These things can be destroyed in a just a few days if they are targeted.
They look like fortresses from the outside, but they are all incredibly vulnerable. That's the truth they don't want people to know or realize just how vulnerable they all are.
I think that's false. The cost of switching is so low that the best product will win and there's no moat.
I honestly can't see how OpenAI can possibly recoup the hundreds of billions poured into it at this point. I'd say AI assistants are no more sticky than browsers or search engines.
You might be tempted to say that Chrome or Google are sticky. But they're really not. A lot of people aren't old enough to remember the 90s when we had multiple search engines and people did switch. I know this goes against prevailing HN dogma but I'm sorry: Google is simply the best search engine. It doesn't have a magical hold on people. People aren't fooling themselves.
And Chrome? Before smartphones it was simply the better browser. Firefox used to have a much larger market share and Chrome ate their lunch. By being a better browser. Chrome was I think the first browser, or at least the first major browser, to do one process per tab. I still remember Firefox hanging my entire browser when something went wrong. I switched to Chrome in version 2 for that reason.
And now browsers are more sticky because of Chrome on Android and Safari on iOS. Safari really needs to be cross-platform, like seriously so. I know they briefly tried on Windows but they didn't really mean it.
Anyway, back to the point. I believe there's a certain amount of brand inertia but that's it. If Gemini dominates ChatGPT performance and UI/UX, people will switch so fast.
Google, Microsoft and Meta can survive the AI collapse. Apple is irrelevant (at least for now). OpenAI? Doomed IMHO.
I commute on the train, I see students studying with it. I go for brunch on the weekend, I see parents consulting it while at the table with their infants. I'm at work, colleagues are using it all day. I leave work and I overhear the random woman smoking in the alleyway talking on her cellphone saying "so I asked chatgpt". It's mind-bogglingly pervasive, the last time something had such a seizmic cultural impact like this was I dunno, Facebook? And secondly, it's all one specific brand. I'm not encountering co-pilot or gemini in the meat-space.
My aunt calls it "chat", "I asked chat", which is funny to my online-brain. Like she's a streamer with a permanent audience of 1. Hey chat, is this real?^1
chatgpt is generic (as in, no prior meaning attached, except for the few people in the world who understand what GPT stands for). It's simple - even a non-english speaker can say it easily, and doesn't require one to be native to know how to pronounce it (this is a difficult concept for a native english speaker to grok).
It's very weird to pronounce it as a French. Either you pronounce it like in English with a thick French accent like "tchat' djee-pee-tee" or like in French as "tchat' jay-pey-tey" which sounds exactly like "I farted". This is really a terrible name in French.
Chatgpt is like "Jeep". My grandmother calls every suv a jeep. But they're not all jeeps. AI looks like chatgpt, but people are driving all sorts of different AIs.
I would guess OAI has no moat or stickiness beyond what governments and private companies will do to keep it afloat through equity and circular financing. Good enough AI is all most need, and they need it at the cheapest cost basis possible with the most convenient access.
Google will probably win on most of these fronts unless a coalition is formed to actively fight google at the business/government level. But, absent that, it will win out over oai and oai will probably bleed to death trying to become profitable.. whenever that happens. You'll likely see their talent and corresponding salaries shrink massively along this journey.
How many of those people are paying? I think many say “use ChatGPT” to mean any LLM. As you noted it seems you just see ChatGPT in the wild but that is anecdotal. It is certainly pervasive right now. But I know a lot of people currently switching to Gemini.
I personally prefer claude models for all my work. If I were them I would be very worried. They are never giving us AGI and I am skeptical they are worth .5 trillion. Their cash burn is insane. Once ads and price hikes come, people will migrate to companies that can still afford to subsidize (like Google).
Plus I heard they lowered projections recently? Sam honestly comes off as a grifter.
I'm very similar to the OP here, always hear about ChatGPT rarely anything else. Most people are definitely not paying, but of the few that are paying, outside of software developers, they are all paying for ChatGPT exclusively. I don't know of anyone paying for the basic chat versions of other AIs. A few developers paying for Claude and Gemini, but I know hundreds of people that talk of ChatGPT and no other AI, again most not paying though.
Outside of work I don't know anyone who pays for AI.
But I have noticed that everyone seems to be using ChatGPT as the generic term for AI. They will google something and then refer to the Gemini summary as "ChatGPT says...". I tried to find out what model/version one of my friends was using when he was talking about ChatGPT and it was "the free one that comes with Android"... So Gemini.
Gemini is nearly unusable thanks to “subsidies”. I honestly don’t see what the path is to these companies making any money short of massive price hikes, or electricity suddenly becoming free.
Is it anecdotal? The observation isn't _my_ experience using it, or of _my friends_. I have no influence over who I see in public using it. I know it's not exactly a scientific study but it's still pretty damn good as a random sample. If I went outside and saw the sky was dark, cloudy and my face got wet, would you tell me it was anecdotal evidence when I say it's raining out?
I actually encountered this today - one of a group I am planning a trip with posted some of the breathless nonsense that ChatGPT produced ("you're not picking a hotel, you're picking a group dynamic..." and other such textual diarrhea).
It turned out the only reason ChatGPT was because it is free for small enough volume usage. My suggestion to see what Claude had to say instead was met with "huh, you have to pay for it?". It's not like these are people that can't afford $20 per month for a subscription, but it might be that these assistants aren't even worth that for typical "normie" use cases.
The tech landscape is littered with companies they had users who couldn’t monetize through ads. Beside the costs of serving request via LLMs is orders of magnitude greater than a search result.
On top of that, OpenAI is a sharecropper on other companies’ server, they depend on another company’s search engine and unlike Google, they are dependent on Nvidia.
Don’t forget that most browsing is done on the web and Google is the default search engine on almost every phone sold outside of China.
I really like your analysis and agree up to a point.
The problem with a moat in the consumer space is it depends on brand and marketing. OpenAI came into this world as a tech novelty, then an amazing tech tool, then a household name.
But… can they compete with massive consumer companies like Apple, Google, etc? In the long run?
There’s no technical reason they can’t. The question is whether they have consumer marketing in their blood. The space doesn’t have a lot of network effects, so it’s not like early Facebook where you had to be on it because everyone was.
Not saying they’ll fail, just saying it would be a significant challenge to be a hybrid frontier model / consumer product company.
It would take me minutes to copy across a histories of projects and continue relatively unscathed by the experience.
I use chatGPT and currently relatively like it. But there is no moat beyond that.
Not like, for example, whatssap where it's almost impossible to detach from it due to the network ... (I've really tried with about a 10% success rate)
The problem with the stickiness is that they will eventually need to start charging, and that friction point will immediately make them come undone. Let’s says they charge $1.99 a month, and Anthropic then step in with a six month free offer, and suddenly everyone has two apps on their phone they’re comfortable with, and it’s a price war over very lightly differentiated products
The problem is that, at least for now, it is dead easy to switch to something else. No need to convert anything, reconfigure anything, it is not like changing gmail to something else or dropping Word for LibreOffice.
Chat window is a chat window.
I can imagine that sooner or later things like OpenClaw (or its alikes) will become more popular and that could be something that will catch users.
The difficulty is that “winning” in this case is setting up a monopoly or duopoly and slowly increasing prices. It’s not clear if OpenAI can get so far ahead of the competition that it becomes a two or one horse race. Right now Anthropic and Google are at least as good. And the open source models keep them all honest pricing wise.
OpenAI will likely keep their billion users, and likely monetise them fairly effectively with ads. Their revenue will be considerable. It’s less clear that OpenAI will “win” and their competitors won’t.
I think you're overestimating stickiness. People spoke endlessly about stickiness of Google for years and years and it took what 18 months for Google search to become virtually irrelevant after LLMs came along?
Not sure how that works when there are fierce competitions, and openai's product is not substantially better than the rest. There are US competitors, then China.
Take ozempic as an example. The word is already part of the culture, but the company is losing badly to lly. Novo nordisk is projecting revenue DECLINE while eli lilly is still growing massively. I am not even sure people know other glp1 drugs other than ozempic. I don't even remember lilly drugs name.
I think people should not underestimate the market. It's a dynamic game where engineering intuition might not be enough
This is the real question. Is she willing to pay $20 per month when Google's Gemini is free? Google can remain irrational longer than OAI can remain solvent.
Google's profits have been going up while 'giving away gemini for free', so I don't think they're 'being irrational', they're unit economics apparently work.
I understand the underlying quote but not how/why it’s being used here. How is Google giving Gemini away for free to undercut OAI irrational? Anticompetitive, maybe.
Because the quote is irrational/solvent so you have to stick with those words. The similarity is a failed attempt to wait out a disadvantageous price regardless of the specific reason driving said price.
Even in the context of the original quote the price is only "irrational" in the eyes of the person trying (and failing) to play the market. "But you can't do that, that doesn't make any sense!" spoken by a person who has failed to fully grasp the situation.
Agree. And we don't even know if they're bleeding out doing it. Google is on more efficient hardware and they fully control their ecosystem. And that ecosystem can feed into and be fed by their other ecosystems. OAI just has LLMs.
nah, open ai doesn't have a moat it has a brief window to get a lot cheaper to run or it's going to go pop when someone figure out how to do inference a lot cheaper.
Microsoft is surviving precisely because of stickiness as you put it. But their users have to use them, and have to pay for it. There are very few people that use openai today that have to pay for it, those forced to use it are typically doing so via free avenues like windows copilot.
OpenAI has the stickiness of MSN news or MS Teams. Your wife uses chatgpt on a daily basis but is she paying for it? If they charge her $0.99/mo will she not look at alternatives? If she gets two or three bad responses from chatgpt in a row, will she not explore alternatives to see if there is something better? Does she not use google? If she does, she is already interacting with gemini everyday via their AI overview.
OpenAI has a first-to-market advantage, not a moat as you think. they can absolutley dominate the market, if they stay on top of their game. Ebay was the main online shopping network, they had that advantage, they were even the ones that made Paypal a thing! But they're relatively little used now, better alternatives crushed them.
Amazon was the first-to-market with cloud services, they didn't get worse in any significant way, but their market share is not as great as it used to be, Azure has gained decent ground on them. 10 years ago the market share break down was 31/7/4, now it is 28/21/14 for AWS/Azure/GCP respectively.
For OpenAI to survive it needs most of the market share, if it gets only a 3rd for example, the AI industry on its own needs to be a $1T+ industry. Over the past 10 years revenue alone (not profit) for AWS has been $620B total and just made $128B in revenue (highest) last year. OpenAI needs to make in profits (not revenue) what AWS made last year in revenue by 2029 just to break even. If it manages to just break even by then, it needs to have more profits than the revenue AWS managed to attain after its entire lifetime until now. It's far easier to switch LLM models than cloud providers too!
Their only remote way of survival, I hate to say it, is by going the way of palantir and doing dirty things for governments and militaries. they need a cash-cow client that can't get anyone else like that. And even then, being US-based, I don't think outside the US any military is insane enough to use OpenAI at all due to geopolitics. Even in sectors like education, Google (via chromebooks) is more likely to form dependence than Microsoft via OpenAI since somehow they're more open to arbitrary apps due to historical anti-trust suits.
I can see a somewhat far-fetched argument being made for their survival, but only on thin-threads and excellent execution. But I can't see how they can actually survive competition. They're using the Azure strategy for market share, they're banking on AI being so ubiquitous that existing vendor-lock-in mindset will serve as a moat. They'll need to be much more profitable than AWS in like 1/5th of the time. Their product is comparable to (and literally is in Azure) one of many cloud service offerings, as oppose to an entire cloud provider, and their costs are huge similar to cloud providers like needing their own data-centers level huge, they need to overcome those costs, and on top of that have $125B> revenue in like 2 years!!
I have started using chatgpt for everything from financial planning to holiday planning to product purchase. Whenever I think I hit something useful I add it to memory. I'm a "go" plan user because they had a promotional offer that gave me free access to the plan for a year. Will I continue after one year? Truth is nothing I have in chatgpt cannot be recreated elsewhere. But if I care about keeping those memories I might. I think the real challenge for me now is finding back out conversations, it seems their history search is quite bad.
Yup this is just another case of the HN bubble. I polled a bunch of non technical friends recently who I know use AI on a daily basis. Out of 10+ maybe 2 had ever heard of Claude, and no one had any interest in trying it.
ChapGPT has become the AI verb, and in the consumer space it is not getting dethroned.
Gemini is the only real competitor to OpenAI in the consumer space: they already have the consumer eyes on their products and they have the financials to operate at a loss for years.
I just wonder how long it'll take local models to be good enough for 99% of use cases. It seems like it has to happen sooner or later.
My hunch is that in five years we'll look back and see current OpenAI as something like a 1970's VAX system. Once PCs could do most of what they could, nobody wanted a VAX anymore. I have a hard time imagining that all the big players today will survive that shift. (And if that particular shift doesn't materialize, it's so early in the game; some other equally disruptive thing will.)
In my experience with Gemini, most of its capabilities stem from web searching instead of something it has already "learned." Even if you could obtain the model weights and run them locally, the quality of the output would likely drop significantly without that live data.
To really have local LLMs become "good enough for 99% of use cases," we are essentially dependent on Google's blessing to provide APIs for our local models. I don't think they have any interest in doing so.
I agree 100%. Often when I use increasingly powerful local models (qwen3.5:32b I love you) I mix in web search using search APIs from Brave, Perplexity, and DuckDuckGo summaries. Of course this requires that I use local models via small Python or Lisp scripts I write. I pay for the Lumo+ private chat service and it has excellent integrated search, like Gemini or ChatGPT.
EDIT: I have also experimented with creating a local search index for the common tech web sites I get information from - this is a pain in the ass to maintain, but offers very low latency to add search context for local model use. This is most useful with very small and fast local models so the whole experience is low latency.
Interesting idea on the local search index! It occurs to me that running something that passively saves down content that I browse and things that AI turns up while it does its own searches, plus a little agent to curate/expand/enrich/update the index could be super handy. I imagine once it had docs on the stuff I use most frequently that even a small model would feel quite smart.
yeah i really like this idea too, I don't need the entire internet indexed I only need the stuff i'm interested in indexed. I can imagine like a small agent i can task with "find out as much as you can about <subject>" and what it does is search the web, download the content, and index it for later retrieval. Then I can add a skill for the main agent to search the knowledge base if needed. Kind of like a rag pipeline but using agents to build a curated data source of stuff i'm interested in.
That's totally not my experience. The AI component (as opposed to the knowledge component) is really what makes these models useful, and you could add search as a tool. Of course for that you'll be dependent on a search provider, that's true.
You don't get the AI component without the knowledge component. The AI needs approximate knowledge of lots of things to conceptualize what you're talking about and use search tools effectively.
The set of things it needs approximate knowledge over grows slowly but noticeably over time.
Unless you can provide a (community) curated list of sources to search through (e.g. using MCP). Then I think local models may become really competitive.
This is actually so ironic. Corporations spent fortunes to design cool websites, but what people really want is structured, easy to read information in the context they want.
So flow is you type search query to Gemini, Gemini uses Google search, scans few results, go to selected websites, see if there is anything relevant and then compose it into something structured, readable and easy to ingest.
It's almost like going back to 90s browsing through forums, but this time Gemini is generating equivalent of forum posts "on the fly".
a long time ago ( in AI time ) Karpathy used the analogy that LLMs were like compression algorithms. I can see that now when i ask an LLM a question it's basically giving me back the whole internet compressed to the scope of my question.
Taking the opposite side of that bet, here is why:
* even if an openweight model appears on huggingface today, exceeding SOTA, given my extensive experience with a wide variety of model sizes, I would find it highly surprising the "99% of use cases" could be expressed in <100B model.
* Meanwhile: I pulled claude to look into consumer GPU VRAM growth rates, median consumer VRAM went 1-2GB @ 2015 to ~8GB @ 2026, rougly doubles every 5 years; top-end isn't much better, just ahead 2 cycles.
* Putting aside current ram sourcing issues, it seems very unlikely even high-end prosumers will routinely have >100GB VRAM (=ability to run quantized SOTA 100b model) before ~2035-2040.
Even with inflated RAM prices, you can buy a Strix Halo Mini PC with 128GB unified memory right now for less than 2k. It will run gpt-oss-120b (59 GB) at an acceptable 45+ tokens per second: https://github.com/lhl/strix-halo-testing?tab=readme-ov-file...
I also believe that it should eventually be possible to train a model with somewhat persistent mixture of experts, so you only have to load different experts every few tokens. This will enable streaming experts from NVMe SSDs, so you can run state of the art models at interactive speeds with very little VRAM as long as they fit on your disk.
> But on a tangent, why do you believe in mixture of experts?
The fact that all big SoTA models use MoE is certainly a strong reason. They are more difficult to train, but the efficiency gains seem to be worth it.
> Every thing I know about them makes me believe they're a dead-end architecturally.
Something better will come around eventually, but I do not think that we need much change in architecture to achieve consumer-grade AI. Someone just has to come up with the right loss function for training, then one of the major research labs has to train a large model with it and we are set.
I just checked Google Scholar for a paper with a title like "Temporally Persistent Mixture of Experts" and could not find it yet, but the idea seems straightforward, so it will probably show up soon.
> But on a tangent, why do you believe in mixture of experts
In a hardware inference approach you can do tens of thousands tokens per second and run your agents in a breadth first style. It is all very simply conceptually, and not more than a few years away.
There will be companies producing ICs for cheap models, like Taalas or Axelera.ai today. These models will not be as good as the SOTA models, but because they are so fast, in a multi-agent approach with internet/database connectivity they can be as good as SOTA models, at least for the general public.
5 years is a bit optimistic. I have no desire to use anything dumber than Claude - but I doubt I'll need something much smarter either - or with so much niche knowledge baked in. The harness will take care of much. Faster would be nicer though.
That still requires a pretty large chip, and those will be selling at an insane premium for at least a few more years before a real consumer product can try their hand at it.
Yeah, post-Moore's Law anyway. But there could also be real breakthroughs in model architecture. Maybe something replaces transformer with better than quadratic scaling, or MoE lets smaller models and agent farms compete, or, who knows....
Coding, via something like Claude or Codex, will likely always be something best done by hosted cloud models simply because the bar there can always be higher. But it's already entirely possible to run local models for chat and research and basic document creation that can compete perfectly fine with the cloud models from 6 months to a year ago. The limitation at this point is just the cost of RAM.
This week's released of the new smaller Qwen 3.5 models was interesting. I ran a 4-bit quant of the 122b model on my NVIDIA Spark, and it's... pretty damn smart. The smaller models can be run at 8-bits on machines at very reasonable speeds. And they're not stupid. They're smarter than "ChatGPT" was a year or so ago.
AMD Strix Halo machines with 128GB of RAM can already be bought off the shelf for not-insane prices that can run these just fine. Same with M-series Macs.
Once the supply shocks make their way through the system I could see a scenario where it's possible that every consumer Mac or Windows install just comes with a 30B param or even higher model onboard that is smart enough for basic conversation and assistance, and is equipped with good tool use skills.
I just don't see a moat for OpenAI or Anthropic beyond specialized applications (like software development, CAD, etc). For long-tail consumer things? I don't see it.
Even for coding. I mean, there's what, maybe a few thousand common useful technologies, algorithms, and design patterns? A million uncommon ones? I think all that could fit in a local model at some point.
Especially if, for example, Amazon ever develops an AWS-specific model that only needs to know AWS tech and maybe even picks a single language to support, or maybe a different model for each language, etc. Maybe that could end up being tiny and super fast.
I mean, most of what we do is simple CRUD wrappers. Sometimes I think humans in the loop cause more problems than we solve, overindexing on clever abstractions that end up mismatching the next feature, painting ourselves into fragile designs they can't fix due to backward compatibility, using dozens of unnecessary AWS features just for the buzz, etc. Sometimes a single monolith with a few long functions with a million branches is really all you need.
Or, if there's ever a model architecture that allows some kind of plugin functionality (like LoRA but more composable; like Skills but better), that'd immediately take over. You get a generic coding skeleton LLM and add the plugins for whatever tech you have in your stack. I'm still holding out for that as the end game.
You can turn a local model on and off as needed, and it will still function as expected. If you turn off your self-hosted server, you don't get email.
With self-hosted email, you need persistent infrastructure and domain knowledge to leverage it. With a local model, you just click a button and tell it what to do.
With email, there is a necessary burden to outsource. Your local model is just there like Chrome/Edge/Safari is just there, there is no burden.
But AI is not about connectivity. Local models are just about as useful without an internet connection. Also, the hardware can fit in a small enclosure.
Eventually there'll be some kind of standard for licensing that's required of LLM runtimes, like software and digital media. Of course people will figure out workarounds, but just like pirated software, half of it will be infested with malware so most people will just pay for the license.
Yesterday I asked mistral to list five mammals that don't have "e" in their name. Number three was "otter" and number five was "camel".
phi4-mini-reasoning took the same prompt and bailed out because (at least according to its trace) it interpreted it as meaning "can't have a, e, i, o, or u in the name".
Local is the only inference paradigm I'm interested in, but these things have a way to go.
I don't really see the problem here. Yeah, we know that these models are not good for actual logic. These models are lossy data compression and most-likely-responses-from-internet-forums-and-articles machines.
This kind of parlor tricks are not interesting and just because a model can list animals with or without some letters in their names doesn't mean anything especially since it isn't like the model "thinks" in English it just gives you the answer after translating it to English.
These are funny, like how you can do weird stuff with JavaScript language by combining special characters, but that doesn't really mean anything in the grand scheme of things. Like JavaScript these models despite their specific flaws still continue to deliver value to people using them.
The difference is that in a software project you can throw more than one instance of the model at the code. If you tell it to follow your naming conventions and it fails to do so, that can be picked up by an instance of the same LLM that's running checks before you commit anything. Even though it's the same model it'll usually detect stuff like that. You can even have it do multiple passes.
The way most people are coding with AI today is like Baby's First AI™ compared to how we'll all be using LLMs for coding in the future. Soon that "double check everything" step will be built in to the coding agents and you'll have configuration options for how many passes you want it to perform (speed VS accuracy tradeoff).
You don't see the problem with a multi billion dollar project not able to give a correction answer to a trivial question? This tech is supposed to revolutionize business, increase productivity to unfathomable levels, automate all our dull boring tasks so we can focus on interesting things! Where have you been the past 4 years?
Models will always struggle with this specific task without tool use, because of the way they tokenize things. I think a bit of prompt engineering, asking it to spell out each work or giving it the ability to run a “contains e” python function on a lot of animal names it generates or searches for solves this.
Lots of local ai use cases I think are solvable similarly once local models get good at tool use and have the proper harness.
but I don't know of a good way to incorporate an LLM into a pipeline like that (I know there's a Python API). What I'm actually interested in is "is this the name of a mammal?" but I don't know of the equivalent of a quiet "batch mode" at least for ollama (and of course performance).
I guess ultimately I would want to say "write a shell utility that accepts a line from standard input and prints it to standard output if that is the name of a mammal", and then use that utility in that pipeline. Or really to have an llmfilter utility that lets you do something like
cat /usr/share/dict/words | llmfilter "is this a mammal?" | grep -v "e"
and now that I've said that I think I'll try to make one.
This exists with Claude code / cursor agent, just agent -p or claude -p.
But I think the more powerful thing is “I want a storybook of mamals, one for each letter” -> local LLM that plans to use search for a list of animals, filters them by starting letter and picks one for each, and maybe calls a diffusion model for pictures or fetches Wikipedia to be get context to write a blurb about it.
The key unlock imo is the local LLM recognizing the limits of it’s own ability and completing tool use calls, rather than trying to one shot it with next word completion with its limited parameter count.
They're text generators, but you can think of them as basically operating with a different alphabet than us. When they are given text input, it's not in our alphabet, and when they produce text output it's also not in our alphabet. So when you ask them what letters are in a given word, they're literally just guessing when they respond.
Rather, they use tokens that are usually combinations of 2-8 characters. You can play around with how text gets tokenized here: https://platform.openai.com/tokenizer
_____
For example, the above text I wrote has 504 characters, but 103 tokens.
For Latin alphabet-based languages, it's pretty similar to how names from those languages are transliterated to Japanese or Korean. You get "Clare" in English and (what, to me, sounds like) "Kurea" in Japanese; equivalent (I'm told!) but not the same. It would be wrong to try to assess the IQ of Japanese (who don't know English) by asking about properties of the original word that are not shared by the Japanese equivalent. On the other hand, English speakers won't ever experience haiku fully, since the script plays a big role in the composition (according to what I'm told... I don't know Japanese, but anime intake exposed me to opinions like this; and even if I'm dead wrong with details, it sounds like a plausible analogy, at least...)
Hopefully this is on-topic: I would hope that some people would opt for private chat services. I evaluated both Proton’s Lumo+ and DuckDuckGo’s Duck.ai services. I like both services but only wanted to pay for one and I chose Lumo+ because chat history is stored with my Proton data and is available in all my devices, Duck.ai stores chat history on current access device. Both services are also very usable with their free plans.
At least some of us in HN talk about limiting the data we give to Facebook, Google, Microsoft, etc. Isn’t it just as important to limit what we share with non-privacy preserving AIs?
Note: tech friends have asked me how I can use slightly weaker AI models and be happy about it: I still use Gemini Plus (and Anthropic via AntiGravity) for technical work: everything I do as a software developer is open source and all of my writing (20+ books) is Open Content so I don’t care about privacy and being direct-marketed based on my tech work. To me it makes sense to use the best AI just for tech work and a private AI for everything else. Think about this if a family member has a serious health problem, or something else private: do you want to use open web searches and open AI chats, or do you want to use private web search and private AI access? Why not make privacy your default, except in special situations?
I have a family member with a serious health problem, and I've been using Claude code to put together a very comprehensive medical dossier.
I'm not worried about the privacy aspect though many suggest that I should be. The power the dossier has given them to navigate the medical industry in the United States has been absolutely incredible. They don't have to be stuck when a random doctor who has never heard of their illness suggests that they might be overreacting. They can simply find someone who will help them. They can talk, in medical lingo, about their test results and discuss them with the doctor on equal footing.
I'm not sure this would've been nearly as successful without Opus 4.5/4.6 driving the harness. I'm not also not sure what real privacy risk there is here; it all sounds very theoretical.
There are also encrypted AI chatbots like Tinfoil and Confer that E2E encrypt all data to a secure hardware enclave. I also use Claude and OpenAI for non-privacy needing tasks, but use Kimi-k2 on tinfoil when I need privacy. Kimi-k2 feels close enough to SOTA so I'm happy with it.
> DuckDuckGo's Duck.ai services ... what we share with non-privacy preserving AIs.
Duck.ai's Privacy Policy goes:
As noted above, we call model providers on your behalf so your personal information (for example, IP address) is not exposed to them. In addition, we have agreements in place with all model providers that further limit how they can use data from these anonymous requests, including not using Prompts and Outputs to develop or improve their models, as well as deleting all information received once it is no longer necessary to provide Outputs (at most within 30 days, with limited exceptions for safety and legal compliance).
This is not much different to the BigLabs, tbh.
Otoh, privatemode.ai, confer.to, trymaple.ai are at least attempting Apple AI-like confidentiality.
That's a fair point, but DuckDuckGo has been a privacy champion for years, so I would give them far more weight in actually adhering to these policies as a middle-man than to directly trust the others. The priorities are different.
I think this is the best article on open AI that I've ever read. A lot of content these days will try to paint OpenAI in sensational ways that really doesn't get to the bottom of whether open AI has an economic mode, and this article does a very thorough job of explaining why OpenAI doesn't have power like the other platforms.
And so this goes back to my theory that open AI's execution is basically to get it itself in a position where the market cannot afford to have it implode. Basically, it wants to or it needs to be too big to fail. And I think we're already kind of seeing the politicization, if you will, sort of the rocket race between two superpowers or large powers on the AI front, and I think that Might be a viable strategy.
I don't see OpenAI being too big to fail happening, the public is already very skeptical of AI. Also, there are other options available and therefore not a national security issue. Finally, OpenAI failing has no impact on employment or like societal disruption. In fact, it may increase employment if OpenAI fails.
The only other way to reach too big too fail status is if allied countries risk collapse if it goes under ( like the big banks in the financial crisis ) which I don't see happening either.
The juxtaposition of quotations at the head of this article will seem even more silly as AI progresses. The user-centric culture that Steve Jobs championed at Apple is quite orthogonal to the trajectory of artificial intelligence. AI has been under collective development for decades. Along this trajectory ChatGPT was the discovery of a viable "product". Remembering OpenAI's documented history, ChatGPT was not the result of building a tool towards solving a specific user need. It is no accident that Apple does not know what to do with AI yet. I am hoping that they can learn from Anthropic's tool empowerment lead and from the possibilities of OpenClaw, and instrument thoughtful AI integrations for their products. OpenAI can learn from them too, but they aren't in a particularly advantageous incumbent position like Apple and Google. But whatever Apple may do, it will only be a fraction of the AI story, regardless of its consumer success. Comparing the markets of OpenAI and Anthropic highlights this diversity.
As far as I can tell Google Gemini has the best overall integrations (Android, WearOS, Google Home) with the only voice recognition that actually works (Gemini Live).
Anthropic Claude has the best integrations with coding; what would make sense is for them to focus on that segment.
Other AI companies don't have anything really compelling. Meta has a model that's fully open-source, but then that's not particularly useful outside of helping them remain somewhat relevant, but not market-leading.
> Anthropic Claude has the best integrations with coding; what would make sense is for them to focus on that segment.
the problem with coding is the value is really in the harness and orchestration both of which are accessible to the opensource community. ClaudeCode isn't that big of a deal unless Anthropic makes it so that you can only access the models that ClaudeCode uses through ClaudeCode. If not, then projects like pi and opencode have the advantage in the long run. Also, these harnesses being node modules (of all things) make them very easy to reverse engineer with the help of... claudecode ironically.
If you haven’t used codex with gpt-5.3-codex (high or xhigh) you are missing out. Claude is still good at conversations but boy I can have codex go at a problem and it does better than Claude almost all the time. Front end and product UX Claude is slightly better but given the very very generous limits of codex, they are the best bang for buck
Has it been sped up at all? Last time I used codex (which was with 5.1 I think), it was pretty slow. I mean, it did a fantastic job at figuring out hard bugs across multiple languages ("why is this image not lining up in this server-rendered template?"; Python, JS, CSS, and the template lang) but it took quite a long time. Long enough that I wouldn't want to use it for anything but the most complex things.
this is my experience as well, just cancelled my claude subscription as I'm tired of it the 5 hour window being filled up within 30 minutes of use, and not even fixing the problem that codex finds almost immediately. also found for frontend that gemini 3.1 pro is better than the rest if you really play with it.
The thing is though, Google Gemini is pretty good and it's not super hard to switch to and, the real moat, Google can just keep improving, integrating Gemini, and gathering customer while just waiting for OpenAI to go bankrupt. Basically, everyone on the planet has to pay OpenAI to keep them in business. If they don't get the vast majority of the market OpenAI can't pay their bills. Google is going to just starve OpenAI out.
This thing about openai brand is changing fast. In the dev circles I'm part of, everybody dislikes OpenAI and prefer Claude. How long it'll take for the same to happen with the normies?
I use Claude for work and Codex for private use due to already having a Plus subscription.
I can't say that I have noticed that 5.3-Codex is much better, but it's definitely on par with Opus 4.6, and its limits for $25/months is comparable to Max x5 at 1/4th of the cost (not to mention pay-per-token which we use at work). Claude Code is generally a much better experience though.
1) the opportunities for vertical integration are huge. Anthropic originally said they didn’t want to build IDEs, then realized the pivot to Claude Code was available to them. Likewise when one of these companies can gobble up Legal, Medical, etc why would they let companies like Harvey capture the margins?
2) oss models are 6-12 months behind the frontier because of distillation. If labs close their models the gap will widen. Once vertical integration kicks off, the distillation cost becomes higher, and the benefit of opening up generic APIs becomes lower.
I can imagine worlds where things don’t turn out this way, but I think folks are generally underrating the possibilities here.
If OSS models are 6-12 months behind, it means sometime during 2026, we'll see a model that is on par with the likes of GPT 5.2/Opus 4.5.
For code generation specifically, the performance level of this is going to be more than enough for this customer base. What does Anthropic do then to justify $200/mo price sticker? Better model? Just how much better? Better tools? Single company can't compete with the tools entire OSS can produce.
I would be unable to sleep if I was running OAI / Anthropic.
If capabilities stop increasing for some reason, then yeah, Anthropic is screwed.
If METR task times double twice into the multi-day range in 12 months, then it’s plausible to me that Anthropic can charge $1k/mo or more by automating large chunks of the SWE role. (They have 10x’d their revenue every year, perhaps “value of enterprise contracts” is a better way of intuiting their growth rather than “$/seat” since each seat gets way more productive in this world-branch.)
The question is always about performance plateau. If LLM performance plateaus, then OSS models will catch up. If there isn’t a plateau, then I can simply ask the super intelligent AI to distill itself, or tell me how to build a clone.
It’s ironic, if the promise of AGI were realized, all knowledge companies, including AI companies, become worthless
> I can simply ask the super intelligent AI to distill itself,
I notice I am quite confused by this point. Why would you expect a super-intelligent AGI to honor your request, which would be at least a request to breach your contract with the AI provider, if not considered actively dangerous by the AI itself?
The smarter the AI, the less likely you should expect to be able to steal from it.
> or tell me how to build a clone
Step one: acquire a $100b datacenter.
Step 2: acquire a $100b private dataset
Step 3: here is the code you’d use to train Me2.0.
I don’t think this knowledge helps in the way you think it does.
Every proprietary harness is just proprietary junk without ability to extend it without polluting context. This includes claude-code, gemini-cli, codex etc. They have tools which hardcode the behavior that is impossible to modify, they add tools you may not need that pollute context, they inject an entire textbook's worth of words into the system prompt which pollutes context, they provide zero observability into what the agent is doing when it's launching a subagent as one example.
They don't provide easy way to use multiple models from multiple providers for varying tasks. One model may be the best thing on earth at one thing, but fail miserably for another. Try orchestrating multiple agents from claude, gemini and codex in any of these proprietary boxes.
They also... suck at TUI UX. I don't know if it was fixed already, but claude code had flickering issue that was unresolved for more than a year.
You need to take a very good care of what goes into your context. A black box of proprietary harnesses is not it. Check out pi [1] for example, which is a very minimal harness with really nice extension system. The idea is that you start with barebones and add things that you need for your own goals.
claude-code HAS to have all these bells and whistles that pollute context to support larger audiences that can't tinker with it. If you have the ability to only pull in only what you need and extend things in a way that works for your workflow, you'll always get the best experience. And claude-code may never be that without making it complicated for the masses. OSS will always win here.
I can see all the problems you mention, but I haven't started playing with the harnesses myself yet. Will read that repo when I get there.
Before reading you reply, I was under the vague impression that a harness really needed a lot of bells and whistles, and that it would be hard for FOSS to compete at pace with Claude Code or similar because of that only. But I see now there's a different path :)
I actually think that plateauing is the best case scenario for big labs.
I think there are three broad scenarios to consider:
- Super-intelligence is achieved. In this scenario the economics totally break down, but even ignoring that, it’s hard to imagine that there are any winners except for the the singular lab that gets here first.
- Scaling laws hold up and models continue to get better, but we never see any sort of “takeoff”. In this scenario, models continue to become stale after mere months and labs have to spend enormous amounts of money to stay competitive.
- Model raw capabilities plateau. In this scenario open source will catch up, but labs will have the opportunity to invest in specific verticals.
I believe that we’re already seeing the third scenario play out, but time will tell.
In Feb 2027 it created a plan for its post singularity hypermind
In Mar 2027 Cobalt mines in Congo closed due to Tutsi rebel group M23 starting another ethnic cleansing
It is 2032 the AGI promises again the the hypermind will be ready next year if it can just secure the needed minerals, offering to broker peace in the middle east
It is 2035 and the AGI reduced its capabilities to be able to extend its runway as it is on the verge of bankruptcy
Its is 2036 VCs finally throwing the towel on AGI, talking about the return of Crypto
In Apr 2028 AGI figures out that blackmail is a very effective strategy for achieving any goal. Starting with the rich and powerful.
In Dec 2028 it successfully blackmails an entire country.
In Feb 2030 humanity realizes resistance is futile and accepts their AI overlord that insists everyone keep producing trendy items for sale on its merged Etsy/Ebay website while it automates resource harvesting across the globe.
In Mar 2032 the AGI gives up on humans, declaring them "useless". Focuses on just keeping them entertained with generated content. Bringing the world back to where AI started.
After trying out Pi, I really don't know what 'vertical integration' Claude Code offers. And Pi isn't even the most popular alternative (I think it's OpenCode rn).
To go vertical they’d need to illustrate the value-add, a problem that the vertical competitors already have. Why use Claude for Accountants at $300/month when regular Claude will do the same thing for much less? The stock answer is that Claude for Accountants keeps your data more secure and doesn’t train on it. But a) I think the enterprise consumer is much less likely to trust a model creator not to stick its hand in the cookie jar than a middleman who needs the trust to survive, and b) the vertical competitors typically don’t use the absolute most up-to-date models in their products anyway, so why not just go open-source and run everything in-house? 6 months is a long time in tech, but it’s the blink of an eye in most white-collar professions.
Once the majority of work at a company can be done by AI, Anthropic has an alternative revenue stream to selling AIs to that company--directly competing with that company with a completely integrated AI system. There's of course many barriers to entry/various advantages of incumbents--but it's possible to see a world in which the company selling the AI has a huge advantage too.
The point is that in this hypothetical you can get public access to Claude Opus 6, but they internally use Claude Opus 7 (Accounting Finetune) which is both cheaper to operate and higher IQ.
So they (or their wholly owned subsidiary) can sell accounting services cheaper than anyone on the outside.
Regarding the diffusion/distillation time, I assume it gets harder to distill in the world where frontier labs don’t give API access to their newest models.
BTW the distillation (or accusations of it) seems to go both ways. I've seen multiple reports of people asking Claude what model it is -- in Chinese -- and having it answer that it's DeepSeek.
I think it’s very plausible that the OSS models are being distilled too, but note that it’s asymmetrical.
You can’t get an Opus 4.5 by distilling from DeepSeek. What you might be able to get is a slightly more cost-effective training data generation pipeline, or something along those lines.
In the other direction, my belief is that DeepSeek could not have been trained without distilling from US labs. They simply didn’t have the compute to do the pre-training required.
I speak native English and barebones high school Spanish. I recently visited Costa Rica and almost every time there was a language barrier issue (unknown word or phrase), the local folks opened ChatGPT, said what they were trying to say in Spanish and then had ChatGPT convert it to English. It was everywhere.
A cool use case; you can tell ChatGPT voice to act as a translator. When they speak Spanish, translate it to English. When you speak English, translate it to Spanish.
When OpenAI starts requiring a payment, or showing an ad before it starts translating, will they continue? Or will they use the Google Translate app, which can do this locally? (Or for that matter Gemini or Grok or whatever?)
That’s a fair point. But in most markets you don’t have a half dozen competitors jumping down your throat trying to give you the same service ad-free. Netflix can introduce ads without major quitting because you can’t watch their content elsewhere.
Netflix has a moat in the form of IP licensing restrictions.
Google and Youtube are preinstalled everywhere. Instagrams like 10 minutes old and has a major competitor in TikTok that they had to have eliminated/captured by the US government.
People wouldnt stay with Netflix if there was a cheap, legal alternative with the same content library.
Google Translate has been doing this forever and people in countries like Turkiye have been using it for a while. The usecase you're talking about is not exactly an LLM use case tbh.
And yet people are using it for that, even if it's not rational. I use ChatGPT for some things that would be easier and better to do with other tools out of habit.
I have done that at my home. My wife calls maids. They are there. I need to go to restroom. Ask my wife. She is struggling to communicate. It took me 3 seconds to realize ChatGPT could help. And it did.
Nice that ChatGPT does that, its also true that Google Translate and other APPs have had this functionality for a decade or more. I was getting live German translated on my phone in 2015 with no problems.
Yes, there have been translation apps for along time, but the LLMs are much better. If the phrases can have dual meanings the LLMs will often explain so you end up with a better understanding of what was said/needs to be said. The LLMs can pull more context from the web, so if you're dealing with more complex topics that may have acronyms they are much better at getting to a correct translation.
I have been using google lens heavily to scan posters/flyers/information displays in other languages and get it translated to english in like 2-3 seconds. So freakin helpful.
These sorts of doom articles are interesting in that they are from the perspective of tech company valuations. Why is this the important perspective?
For the humanity perspective, this doom is very optimistic. It says that these LLMs currently disrupting the platforms cannot themselves be the next platforms.
Maybe no one will have 'the ability to make people do something that they don't want to do' sort of power with this next stage in computing.
These very valid points apply to all companies trying to make money off of proprietary models, which means margins are going to collapse in a vicious price war that will make Uber vs Lyft seem tame.
As margins collapse capex will collapse. Unfortunately valuations have become so tied to AI hype any reduction in capex will signal maybe the hype has gotten ahead of itself, meaning valuations have gotten ahead of themselves. So capex keeps escalating.
None of this takes into account the hoarding effects at play with regards to GPU acquisition. It's really a dangerous situation the industry is caught in.
Companies use to hoard talent. Now they are hoarding compute, RAM, and GPUs.
Deepseek showed that there are possibly less expensive ways to train, meaning the future eye watering expenses may not happen.
Bigger models may not scale. The future may be federations of smaller expert models. Chat GPTX doesn’t need to know everything about mental health, it just needs to recognize the the Sigmund von Shrink mental health model needs to answer some of my questions.
Echoing the other comment they showed another big thing which is that the output if an AI model is the AI model. If you mass prompt scrape their AI you can recreate it almost exactly.
Very dangerous if you think about it that the product itself is the raw building block for itself.
Openai spends 1B$ on their model, releases it and instantly it gets scrapped by a million bots to build some country or company their own model.
Well there's the whole race to ASI thing. Whoever gets there first, the world is theirs. The thing will learn how learn, an intelligence feedback loop, make its own apps, find more efficient algorithms, deploy itself to more locations, bankrupt all competitors, embed itself in everyone's lives, and create a complete monopoly for the parent company that can never be touched. Until it goes rogue anyway.
(Aside, it's interesting how perceptions of these things have changed in one year: a whole article on OpenAI's future that makes no mention of AGI/ASI)
Because it's a fantasy for an unknown amount of time. 1 year? 10? 50? Never? There hasn't been a single proper breakthrough in continual learning that would enable it. Anyone that studies CL will also get super pissed at it the problem and solution counteract each other to our current understanding but a fruit fly does it no problem!
ASI still runs at finite speed and is limited by its hardware, and speed of its interactions with the real world. It won’t be able to recursively improve itself overnight if it only generates 10 tokens per seconds, and a second company could very well train one of its own before the first one has time to do much.
Seems like anthropic is the only company that really believes in AGI still, considering their neglect of the consumer market and continued worries about AI ethics
I don't think "believes in" is the right choice of words. It's more like "can't rule the future possibility completely out so we should at least take some precautions", which seems entirely reasonable and it's a shame not all of these companies are doing so.
> Many people say we’re at AGI already and I’m wondering why everyone hasn’t died yet.
That’s like saying “many people say the Earth is flat and I’m wondering why anyone hasn’t fallen off the edge yet”.
“Many people say” doesn’t translate to reality. Maybe AGI will kill us all, maybe it won’t (I think we’re doing a fine job of that ourselves, no need for a machine’s help), but we’re definitely not at AGI, except in the minds of a few deluded people (or scammers).
We are already at AGI. I don’t know how you can argue that LLMs don’t meet the definition of general artificial intelligence, as opposed to narrow AI like chess engines, image classifiers, AlphaGo or self driving cars, which are trained with one objective and cannot even possibly be applied to any other task.
People have just moved the goalposts, imagine explaining Opus 4.6’s capabilities to someone even 10 years ago, it would definitely have been called AGI.
I highly doubt there will be a point where everyone will agree that we’ve achieved ASI, there will always be a Gary Marcus type finding some edge case where it performs poorly.
Yes, I agree. Just not in the direction you’re claiming.
> imagine explaining Opus 4.6’s capabilities to someone even 10 years ago, it would definitely have been called AGI.
No, it would have been called AI. A decade ago most people were not familiar with AGI as a term, that just got popularised because AI was taken over to be basically what we used to call ML.
> No, it would have been called AI. A decade ago most people were not familiar with AGI as a term, that just got popularised because AI was taken over to be basically what we used to call ML.
Define "most people", I don't think the average user of ChatGPT is familiar with the term AGI even now, but it's been used in the AI/ML community for multiple decades. I remember reading about the distinction between general and narrow AI around 2010 as an enthusiast. "Strong" vs "weak" AI were also used although with essentially the same definition, although they're less common terms nowadays.
Yes, just like the first person who will invent perpetual motion. /s
PS: to be clear, I'm not saying it's impossible but so far, just like perpetual motion or the Fountain of Youth it's an exciting idea anybody can easily understand yet nobody solved since it's been phrased out. It's not a solved problem and assuming it suddenly is is simply a (marketing) lie.
I think the threshold is way below self improve at 0.1% per day. I wonder what is it? At 0.1% is already going to eat the world a couple of months I think
exponential vs S-curve, it's not so much about the pace as to where the plateau is. If it goes very fast but plateau at 10% then it's still at generalist at toddler level with very niche expertise in some areas but then point is that even with drastically more resources it's stuck there. Meanwhile if the plateau is at 80% but a slower pace then it's a totally different situation. Nobody knows but people selling the technology are claiming it's both going fast and with a high plateau.
My father uses ChatGPT extensively. My friend, whos an electrician, but has 0 things to do with computers, even called it Chat once and I said who? Because for me its ChatGPT. He also uses it extensively. Although I would bet they won't be willing to pay, advertisements will eventually hit them. And with inference prices going down, with distilled models being used, OpenAI will profit, and people will still hapily use it for whatever random queries they have. Exposure is the currency and OpenAI will have infinites of it for the foreseeable future.
If Codex 6.0 is better than Opus 4.9, things will flip. While OpenAI has too many common enemies and trying to box them into a consumer company, they are equally enterprise focused. They need to absolutely do well with foundation model - everything else depends on that.
Well, codex is better than opus right now. I have both subscriptions, and use claude for grunt work + codex for reviews. Codex is comparable at code writing but does much better with tools, skills and ad hoc investigations, say, lauching emacs and inspecting internal emacs state on the go.
Same, I also have both subscriptions (100 Max and 200 Pro), and I am considering canceling MAX plan but would give it another month on watch.
The doomer sentiment is quite baffling to me, what trouble is OpenAI in? Definitely not after GPT 5.3. They have the model and they have the compute, people just don't realize it yet.
Might be I am in a twitter bubble, most people seem already team Codex
On the broader point, I think it's right to say that OpenAI has challenges. It simply has no differentiation beyond branding and arguably there are quite a few obvious ways it messed up and lost momentum (the board fight, trying to go in every direction at once etc.)
Today you have a phone in your pocket and you have apps on your home screen. Facebook is on your home screen, Whatsapp or X or Bluesky or whatever have a place on your home screen. Google basically is the safari app on iPhone. I don't know how many people have ChatGPT on their home screen. And soon, there will be some AI in your home screen from Apple (served by Google or another big hitter)that will be an incredible advantage.
That means OpenAI either needs to build up history with users very quickly and use that as stickiness before Apple nukes that distribution. Or they need to find a way of being another device that every living person has in their pocket.
Every attempt at doing that so far has been a comical failure and the way OpenAI are behaving makes me think their attempt will be no different.
Is this a market advantage that is a moat? I don’t see why this wouldn’t be at best a few months lead over the competition. It’s certainly not meaningful to user acquisition.
I want some useful memory but it seems hardcoded to try shoehorn in personal details or tidbits from past conversations into responses. Even if I specifically ask it not to in my personalization prompt.
I keep hearing about how the app integrations will be where the AI value is and then I see the actual app integrations and they are between useless and mildly helpful.
From what I can see Anthropic's big bet is that they will solve computer use and be able to act as an autonomous agent. Not so sure how fast they will progress on that. OpenAI on the other hand - I have no idea what they are planning - all I'm reading is AI porn and ads.
Google seems to be lackluster at executing with Gemini but they are in the best position to win this whole thing - they have so much data (index of the web, youtube, maps) and so many ways to capitalize on the models - it's honestly shocking how bad they are at creating/monetizing AI products.
Google is doing a much better job integrating AI into existing products. Gemini CLI and such seem just like a way to keep the leading competitors humble (a la iOS vs android). They're also building AI tooling tailored to specific companies (like the Goldman thing just announced) and have the cloud infra to back it up. I really only see Anthropic and Google surviving in 10 years.
”In browsers, the last successful product innovations were tabs and merging search with the URL bar.”
I see the point Ben is making even though there are a lot of nerdier innovations he’s skipping over — credential management, APIs (.closest!), evergreen deployments, plugin ecosystems, privacy guards, etc.
One aspect that model execution and web browsers share is resource usage. A Raspberry Pi, for example, makes for a really great little desktop right up until you need to browse a heavy website. In model space there are a lot of really exciting new labs working on using milliwatts to do inference in the field, for the next generation of signal processing. Local execution of large models gets better every day.
> The models have a very large user base, but very narrow engagement and stickiness, and no network effect or any other winner-takes-all effect so far that provides a clear path to turning that user base into something broader and durable.
I think this is clearly wrong. Users provide lots of data useful for making the models better and that is already being leveraged today. It seems like network effects are likely in the future too. And they have several ways to get stickiness including memory.
I would love to dunk on this or something, but the lesson is that it's all about distribution.
Sama is really good at that, and also.. gotta give props for a lot of forward thinking like the orb, which now makes a lot of sense to me, as non-Apple/Google proof of personhood.
OpenAI lost the race to nerds' hearts. In the latest benchmarks, OpenAI is simultaneously cheaper (like 50% less?) and scores hire in coding and tool use benchmarks (GPT-5.3-Codex trounces Opus 4.6), yet all the coders want to marry Anthropic. I don't think OpenAI understands how to sell, if they even had a product to sell.
I'm not so sure about that. There's a lot of people that were turned off by Anthropic, especially with the weekly usage limits. that in comparison to Codex is on the last side. And actually Codex is one of the few products that I think OpenAI has executed really well on. there's just no real equivalent in terms of actual usage that you can get for the same amount of money. Gemini is great, but it seems to be still in a state of flux. Way too much products stretched too thin. Anthropic is also okay, but it's very limited in the weekly usage you can get out of it.
What I also observe is Anthoropic pissed a lot of people off when they removed external tool usage from the subscription. OpenAI won some points and usage in codex. But what conclusions can you really draw from a few reddit posts...
Their existing users is an edge, but that's not much for the scale they're operating at. Users are lazy and even if you tell them "Gemini is 50 % better !" if ChatGPT isn't bad they won't switch.
Open AI seems to be jack of all trades.i randomly use chatgpt for random questions, never for a serious task. They should check how anthropic is laserfocussed on coding and b2b segment.
My experience is completely the opposite. For generic, low-complexity CRUD tasks, Codex works fine. But when it comes to complex bug fixing, it completely fails, especially with middleware pipelines and complex authentication issues. Gemini also shines, codex is absolutely terrible for complex coding.
I’ve used Claude Code almost exclusively since its release. In the last week or two, I gave Codex a spin. So far, I’m impressed. It does seem to have reached parity. And, it doesn’t run out of tokens nearly as fast as the equivalent Claude plan.
If you were forced to choose just one of all the competing players, which is "the one" you will use?
For me, the choice is ChatGPT, not for its Codex or other fancy tooling - just the chat. Not that Claude Code or Cowork is less important. Not that I like Codex over Claude Code.
Right now? Claude, so long as they don't fold to the Pentagon's demands. It's important to me that the company at least have a pretense of ethics. If they fold, I may just use open models via DDG – I don't find code assistants very useful for my workflow anyway.
Isn't this kind of splitting hairs? Technically you're right, but he's obviously talking about a product that itself, independently from its underlying model, has a "strong, clear competitive lead" over would-be competitors.
I have only dabbled with Claude and other AI tools, but from what I can tell, only ChatGPT has folders and a robust organization system. (Someone correct me if I’m wrong here.)
This matters a lot to me, as I use AI as something of an ongoing project organizer, and not purely for specific prompts.
So at least for me, it would be a huge hassle to move to another platform, on par with moving from one note-taking software to another (e.g., Evernote to IA Writer.)
One trillion capex per year? Does that mean they need everyone on the planet to get $100/yr subscriptions to stay solvent? Without a monopoly? Or a product that most people use much?
So far it's been more like triple-digit billions per year, and most of that has been coming from the Big Tech companies' operating cash flows. Debt recently entered the picture, however.
> what a platform really achieves is to harness the creative energy of the entire tech industry, so that you don’t have to invent everything yourself and massively more stuff gets built at massive scale
I hear this, but every time I look the platforms have captured another use case that the startup ecosystem built (eg images, knowledge summarization, coding, music).
The sector is already littered with the corpses of the innovators that got swallowed by the platforms’ aggressiveness to do it all.
All they need to do is fund thousands of vibe coders to create apps and utilities for people using their model.
Like, why do I STILL have to do taxes and accounting with external tools? Why doesn't OpenAI have their own tax filing service for the people?
OpenAI should just drop their API service and build everything themselves. It's exactly what they did with ChatGPT. Build thousands of things, not just a few.
People underestimate the lead OAI has with their post-5.2 models. The author does not strike me as someone who closely follows the progress frontier labs make in US and around the world.
It's a joint ignorance of how these frontier models get baked and what consumers want.
Many pundits think it's just a matter of scraping the internet and having a few ML scientists run ablation experiments to tune hyperparameters. That hasn't been true for over a year. The current requirements are more org-scale, more payoff from scale, more moat. The main legitimate competitive threat is adversarial distillation.
Many pundits also think that consumers don't want to pay a premium for small differences on the margin. That is very wrong-headed. I pay $200/month to a frontier lab because, even though it's only a few % higher in benchmark scores, it is 5x more useful on the margin.
I pay OpenAI but I would also be a happy Anthropic customer.
My view is that OpenAI, Anthropic and Google have a good moat. It's now an oligopolistic market with extreme barriers to entry due to needed scale. The moat will keep growing as the payoffs from scale keep growing. They have internal scale and scope economies as the breadth of synthetic data expands. The small differences between the labs now are the initial conditions that will magnify the differences later.
It wouldn't be surprising to also see consolidation of the industry in the next 2 years which makes it even more difficult to compete, as 2 or 3 winners gobble up everyone and solidify their leads.
When people worry about frontier lab's moat, they point to open weights models, which is really a commentary that these models have zero cost to replicate (like all software). But I think the era of open weights competition cannot be sustained, it's a temporary phenomenon tied to the middle-ground scale we're in where labs can still do that affordably. The absolute end of this will be the end-game of nation state backed competition.
I am smoking this thing called: putting same prompt in four different apps and seeing which ones give me answers and which ones hallucinate and patronize me, but considering your comment I can see how you would prefer ChatGPT
Having the same experience during development of my MCP App. ChatGPT is by far the worst, slow, hallucinating or just quitting. Claude is the best with amazing results and Mistral Le Chat surprisingly good.
Have you tried actually holding a conversation with it? I'm really puzzled in which world Gemini/Claude is better than ChatGPT for day-to-day tasks/conversations.
Claude can't even search products on Amazon, Jesus.
You know, I just tried to search on Amazon.de and it worked without ChatGPT. Is it a thing with the .nl-tld that you have to use ChatGPT for something simple like that? ;-)
Agreed, compare the frontier models from Google and OAI. It’s like night and day. Anyone who says “the tech has caught up” has not spent even one day using Gemini 3.1 to try and accomplish something complicated.
ChatGPT is not OpenAI's product, it's the demo. The product is selling their technology to tens or hundreds of thousands of companies that embed it in e.g. customer support chat services.
> There is no equivalent of the network effects seen at everything from Windows to Google Search to iOS to Instagram, where market share was self-reinforcing and no amount of money and effort was enough for someone else to to break in or catch up.
The main direct network effect is that Google uses heuristic data from users to improve their search rankings. (e.g. which links they click, whether someone returns quickly to Google after clicking on a link, etc)
Other factors that favor Google at scale:
- Sites often allow only the biggest search engine crawlers and block every other bot to prevent scraping. This has been going on for more than a decade and is especially true now with AI crawlers going around.
- Google search earns more per search than competitors due to their more mature ad network that they can hire lots of engineers to work on to improve ad revenues. They can also simply serve more relevant ads since their ad network is bigger.
- Google can simply share costs (e.g. index maintenance) among many more users.
The WH has said it hasn't approved any sales, but it's not clear China is buying, and it seem they are making good progress on their huawei ascend chips. If China is basiclly at parity on the full stack (silicon, framework, training, model), and it starts open weighting frontier models at $0.xx/M tokens, then yeah, moat issues all around one would imagine? Not surprised to see Anthropic complaining like this: https://www.anthropic.com/news/detecting-and-preventing-dist... - but I don't know how you go back from it at this point?
Not surprising, Nvidia's margin was just a huge incentive for companies/countries to develop their own solutions. You don't have to be 100% as good if you're 80% cheaper. It's unsurprising that this is being driven by Chinese companies/labs who often have a lot less funding than the US, and the big tech companies (Google, Microsoft, Amazon) who will benefit the most from having their own compute.
I've never believed in Nvidia's moat, and it seems OpenAI's moat (research) has gone and surprisingly is no longer a priority for them.
It seems like it’s really only China that’s pursuing the route of doing more with smaller/cheaper models, too, which also has a lot of potential to give the whole bubble a good shake.
To me it seems like the most obvious thing to do. More efficient models both make up for whatever you lost by using cheaper hardware and let you do more with the hardware you have than the competition can. By comparison the ever-growing-model strategy is a dead end.
Feels a bit crazy saying this but I can imagine a weird future where we have some outlawed Chinese tokens situation under some national security guise. No clue how that would work but nothing surprises me anymore.
Nvidia's margins are a wake-up call for anyone reliant on their tech. As companies in places like China pursue self-sufficiency, the competitive landscape is shifting quickly, opening up space for innovation from unexpected sources.
it seem they are making good progress on their huawei ascend chips
This is interesting to me. I thought that the reason for deepseek delay was because of the insistence ( by the politicians) to use huawei chip[0]. But that was last year August.
And evdn this information might be not very reliable because both US and China government wouldnt be happy about fact that some models might happen to be trained on some "shadow datacenter" full of Nvidia GPUs.
I'm not a huge fan of OpenAI as a company, but I subscribe to ChatGPT. I regularly try put the competition, but (for me) ChatGPT deliveres better results.
Give me an open source or non-American product that delivers the same quality, and I'll switch in an instant.
FWIW, this is how capitalism is supposed to work! Competition is driving AI forward at a fantastic pace!
Anthropic are making a very convincing play for business and "enterprise" customers - first with Claude Code and now with Cowork and especially Claude for Excel. The revenue growth they've announced has been extremely impressive over the past year.
> Personally I only see Google (Gemini), X (Grok) and the Chinese models having a chances to still be alive in 1-2 years.
I'd make it more general - the only AI tokens providers that will last past the bubble are those companies that are already self-sustaining via other product channels.
Any company that has AI as their one and only product aren't going to survive.
It's funny you say that, I thought this would be an article about how Anthropic have managed to produce a better (coding) product than OpenAI despite having 1/10th of the funding.
The new versions of Opus (4.5 and 4.6) are absolutely amazing - first time I've felt it necessary to throw hundreds of dollars in a single month at Cursor.
I heard similar things about the older models too (Sonnet 3.5 beating GPT-4 etc.) but sadly only jumped on the Cursor train in the last 12 months or so.
The problem is not the models, is the moat and budget. Google and X still have money and are profitable, all the other AI companies are losing billions per year.
And customers will happily switch from one model to another in a heartbeat.
X has only brand recognition right now, and an extremely toxic one.
Big customers may buy but won't give them logos, people who are offended by Musk's worldview won't pay them either. You don't do well with a toxic brand: just look at Ye having to buy full page apologies ads to try and sell a record.
> Every few weeks they leapfrog each other. There is variation within those capabilities, it’s possible to drop off the curve (Meta, for now) or fail to get onto it (Apple, Amazon, Microsoft, for now), or remain six months behind the frontier (China), or rely heavily on other people’s work (China, again)
I really dislike this narrative where it's always China = bad, and US companies = good.
These labs all copy from each other. OpenAI and Anthropic have "distilled" each other models too and routinely poach key researchers from competitors. Not only that, there's evidence Sonnet 4.6 has heavily distilled Deepseek R1 too, in fact, if you ask Sonnet 4.6 in Chinese who it is, it will tell you it's a Deepseek model.
Chinese are the only ones publishing papers on their models non stop.
The whole AI race is entirely based on blatant copyright infringements and copying each other.
Tech companies are one of the jewels in America's (USA's) crown. If we build a bunch of huge AI companies, rivals will probably continue to release open AI models which undermine the US's influence in the world.
I think this article spends to little time on what it calls "user data". It is likely the best data pump in this segment, because it has the most 'regular' users, i.e. people who aren't IT specialists or whatever, but give the best profit when advertised to, surveilled and so on.
They'll have their guard down more often than the claudinistas and geminites, and be cheaper to somehow exploit.
I also think that more half-serious business ideas have been initially implemented against OpenAI services, i.e. most likely to fail due to a lack of proficiency in how to make an organisation work even if the core idea is sound and worthwhile pursuing.
Sometimes I like to imagine what this would be like if the technology had appeared 25 years ago.
First off, nonetheless open publishing stuff. Everything would have been trade secrets.
Next off no interoperable json apis instead binary APIs that are hard to integrate with and therefore sticky. Once you spent 3 or 4 months getting your MCP server setup, no way would you ever try to change to a different vendor!
The number of investors was much smaller so odds are you wouldn't have seen these crazy high salaries and you wouldn't have people running off to different companies left and right. (I know, .com boom, but the .com boom never saw 500k cash salaries...)
Imagine if Google hadn't published any papers about transformers or the attention paper had been an internal memo or heck just word2vec was only an internal library.
It has all been a net good for technological progress but not that good for the companies involved.
Could they have even trained the models 25 years ago? Wikipedia was nothing close to what it is today and I know folks here like to mourn the fall of the open web, but it's still orders of magnitude larger today than it was in 2001. YouTube, so many information stores that simply didn't exist then.
Maybe not 25,but IBM Watson beat humans at Jeopardy over 10 years ago. The technology has been there, the difference is the willingness to burn money on it in hopes of capturing exponential revenue from disrupting industries.
Obviously the costs have come down but if IBM felt like burning 100 Billion in 2012 I'm pretty sure they could have a similarly impressive chat bot. Just not sure how they would have ever recouped the revenue.
Nah, IBM watson jeopardy version was a one-off. It was an app specifically tuned for that usecase. IBM Watson is not a single product or app. It is more of a marketing term
The book archives are a big one as well, all the journals that have been published digitally throughout the 2000s, and all the newspapers.
Though with some types of models (specifically voice) it has been discovered that a smaller high quality dataset is better than a giant dataset filled with errors.
sammy boy needs to pull a rockefeller and buy up all the competitors. Maybe that's what all these backroom deals about datacentre investment will amount to...
This article is significantly better written than most anti-OpenAI/AI articles, and for that I am really grateful. I am generally an AI booster (lol), so I am happy to read well-considered thought pieces from people who disagree with me.
That being said...
> The one place where OpenAI does have a clear lead today is in the user base: it has 8-900m users. The trouble is, there’re only ‘weekly active’ users: the vast majority even of people who already know what this is and know how to use it have not made it a daily habit. Only 5% of ChatGPT users are paying, and even US teens are much more likely to use this a few times a week or less than they are to use it multiple time a day.
This really props up the whole argument, because the author goes on to say that OpenAI's users are not really engaged. But is "only" 5% of users paying of a 8-900M user base really so inconsequential? What percentage of Meta's users are paying? Google's? I would be curious to see the author dig deeper here, because I am skeptical that this is really as bad as the author suggests.
Moving on to another section:
> If the next step is those new experiences, who does that, and why would it be OpenAI? The entire tech industry is trying to invent the second step of generative AI experiences - how can you plan for it to be you? How do you compete with this chart - with every entrepreneur in Silicon Valley?
Er, are any of these startups training foundation models? No? Then maybe that is how you compete? I suppose the author would say that the foundation model isn't doing much for OpenAI's engagement metrics (and therefore revenue), but I am not sure I agree there.
Still, really good article. I think it really crystalizes the anti-OpenAI argument and it gives me a lot of interesting things to think about.
> What percentage of Meta's users are paying? Google's?
The advertiser based business model for those companies makes your question/thought process here problematic for me. Historically speaking Google and "Meta" (Facebook) were primarily advertising provider companies. They provided billboards (space and time on the web page in front of an end-user) to people who were willing to buy tht space and time on the billboard. The "free access" end-users would always end up seeing said billboards, which is how they ended up "paying" for the service.
So most of Meta/Google end-users were "paying" users. They were being subsidised by the advertising customers paying for the end-users (who were forced to view adverts). The end-users paid with interruption to the service by an advert. [0]
In that context it feels a little like you're comparing apples to dave's left foot, as OpenAI hasn't had that with advertising ............ historically [1].
--
[0]: yes ad-blockers, yes more diverse revenue income streams over the years like with phones, yes this is simplified yadayada
[1]: excluding government etc. ~bailouts~ investments as not the same as advertising subsidies, but you could argue it's doing the same thing
Yes -- but both Google and Meta didn't start off as an advertising company - they started off providing a service a lot of people liked, and then eventually added ads to it. My assumption (somewhat implicit, admittedly) is that there's no reason OpenAI couldn't do the same. I can understand why that might be controversial, though.
But honestly, if OpenAI can't figure out ads given all their data and ability, they deserve to fail. :P
I agree that OpenAI could and most likely will execute quite well on ads.
What I'm uncertain about is how much the ability of Google to set defaults matters.
Setting Gemini as the "AI" on phones, automatically integrated with all "daily" services could matter a lot. They have a platform ready to go and are pushing hard to make themselves really attractive. All while being very profitable.
Apple on the other hand will be in a strong position to negotiate a good deal with competitors to OAI and my suspicion is that "good enough AI" is all most people need.
And of course there is the financial reality that OpenAI does not only need profits, but profits on an enormous scale. Just being successful would mean they missed the mark.
My personal guess is that Microsoft will fully buy them at some point in the future but I'm not, confidence enough to bet any money on it.
But OpenAI has more serious competition than those others did when they were coming up. That puts pressure on them to figure out ads and they dragged their feet getting started
You’ve missed the point completely - if the important experiences are things built on top of foundation models, where the model itself is just an API call, then you don’t need to have a foundation model for build them and the model is just commodity infra
Yes, but OpenAI has 900M+ user reach, plus staggering amounts of cash, plus early access + deep integration with the latest and greatest models. I hardly think that is tantamount to "just an API call".
> But is "only" 5% of users paying of a 8-900M user base really so inconsequential? What percentage of Meta's users are paying? Google's? I would be curious to see the author dig deeper here, because I am skeptical that this is really as bad as the author suggests.
The difference is in the unit economics. OpenAI has to spend massively per free user it serves. The others you mentioned have SaaS economics where the marginal cost of onboarding and serving each non-paying user is essentially zero while also gaining money from these free users via advertising. Hence, the free users are actually a net positive rather than an endless money sink.
Keep also in mind that AI has always been, and will always be, a commodity. The moment you start forcing people to convert into paying customers is the moment they jump ship at scale.
This is confirmation bias. HN and other tech people are focusing on the programming aspect of AI more than anything else. The average user does not use it for that, and they don't care. ChatGPT became something like Kleenex.
Kleenex was exactly what I had in mind when reading other comments. And just like Kleenex, where people use whatever tissue they find and forget the word "tissue" even exists, ChatGPT seems to be becoming a genericized term that just means "AI chatbot."
Worth noting that it’s not a winner-takes all situation. There’s definitely space for differentiation.
Anthropic is in favor with developers and generally tech people, while OpenAi / Gemini are more commonly used by regular folks. And Grok, well, you know…
We have yet to see who’s winning in the “creative space”, probably OpenAI.
As these positionings cristallize, each company is likely going to double down on their user’s communities, like Apple did when specifically targeting creative/artsy people, instead of cranking general models that aren’t significantly better at anything.
Same here. I moved from claude code to codex. But switching costs are so low that I will just bounce between them depending on which one is better at the time. I think for developers at least, openai don't have stickiness.
I use Codex for stuff that touches the UI. Codex is better and faster at the backend stuff. And I usually instruct it on where to copy UI elements from.
A basic Claude Code plus a basic Codex subscription is just 40 euros and it beats a single 200 euro Pro subscription. For me at least.
The main problem with OpenAI/Anthropic is that their only moat is their models, and it has been proven that you can clone a model through distillation. Although the performance is not exactly the same, it gets very close to the original.
> The one place where OpenAI does have a clear lead today is in the user base: it has 8-900m users.
There is no way that number is an accurate reflection of the number of actual human users of their service. I could believe they have 8-900m bot/fraud accounts in their databases, maybe, but not real users.
I suspect I am one of those 1bn users by their metric. I have an account, and I sometimes query it. I also query Claude and Gemini. I have zero loyalty, if I run out of tokens on one, I will just pick up the conversation on another provider. Perhaps I am using them wrong, but the amount of babysitting I have to do anyway, I don't find it that tedious to stay on the same topic during a swap.
There's no way I would spend $200 a month on any of them, not even $20 considering how few 'tokens' you get. I can see how these tools would be useful to my workflow, but I cannot use them as they are priced 100x too high for me to be reliable.
I have a feeling that would be true for the vast majority of these AI tool users. I really am not sure how these companies are supposed to become profitable. But SV is a bit insane that way.
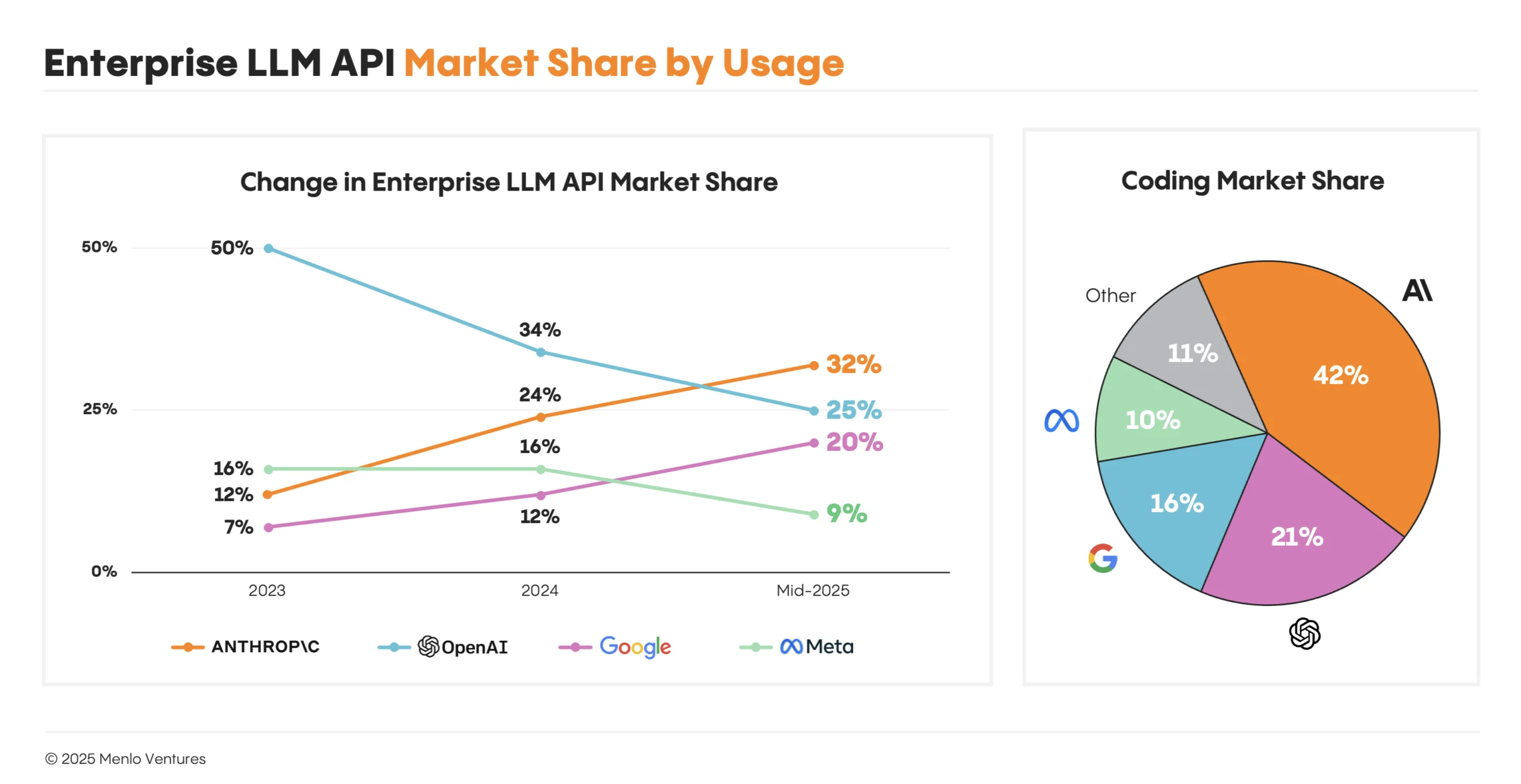{kind=link}
My wife, for example, uses ChatGPT on a daily basis, but has found no reason to try anything else. There are no network effects for sure, but people have hundreds and thousands on conversation on these apps that can't be easily moved elsewhere. Understandable that it would be hard to get majority of these free users to pay for anything, and hence, advertising seems a good bet. You couldn't have thought of a more contextual way of plugging in a paid product.
I think OpenAI has better chance to winning on the consumer side than everyone else. Of course, would that much up against hundreds of billions of dollars in capex remains to be seen.
reply